Hammer User Guide
Hammer is optimized for Purdue's communities utilizing loosely-coupled, high-throughput computing.
Link to section 'Overview of Hammer' of 'Overview of Hammer' Overview of Hammer
Hammer is optimized for Purdue's communities utilizing loosely-coupled, high-throughput computing. Hammer was initially built through a partnership with HP and Intel in April 2015. Hammer was expanded again in late 2016. Hammer will be expanded annually, with each year's purchase of nodes to remain in production for 5 years from their initial purchase.
To purchase access to Hammer today, go to the Cluster Access Purchase page. Please subscribe to our Community Cluster Program Mailing List to stay informed on the latest purchasing developments or contact us via email at rcac-cluster-purchase@lists.purdue.edu if you have any questions.
Link to section 'Hammer Specifications' of 'Overview of Hammer' Hammer Specifications
Most Hammer nodes consist of identical hardware. All Hammer nodes have variable numbers of processor cores, and 10 Gbps or 25 Gbps Ethernet interconnects.
| Front-Ends | Number of Nodes | Processors per Node | Cores per Node | Memory per Node | Retires in |
|---|---|---|---|---|---|
| 2 | Two Haswell CPUs @ 2.60GHz | 20 | 64 GB | 2020 |
| Sub-Cluster | Number of Nodes | Processors per Node | Cores per Node | Memory per Node | Retires in |
|---|---|---|---|---|---|
| A | 198 | Two Haswell CPUs @ 2.60GHz | 20 | 64 GB | 2020 |
| B | 40 | Two Haswell CPUs @ 2.60GHz | 40 (Logical) | 128 GB | 2021 |
| C | 27 | Two Sky Lake CPUs @ 2.60GHz | 48 (Logical) | 192 GB | 2022 |
| D | 18 | Two Sky Lake CPUs @ 2.60GHz | 48 (Logical) | 192 GB | 2023 |
| E | 15 | Two Intel Xeon Gold CPUs @ 2.60GHz | 48 (Logical) | 96 GB | 2024 |
Hammer nodes run CentOS 7 and use Slurm (Simple Linux Utility for Resource Management) as the batch scheduler for resource and job management. The application of operating system patches occurs as security needs dictate. All nodes allow for unlimited stack usage, as well as unlimited core dump size (though disk space and server quotas may still be a limiting factor).
On Hammer, the following set of compiler and math libraries are recommended:
- Intel 17.0.1.132
- MKL
This compiler and these libraries are loaded by default. To load the recommended set again:
$ module load rcac
To verify what you loaded:
$ module list
Link to section 'Accounts on Hammer' of 'Accounts' Accounts on Hammer
Link to section 'Obtaining an Account' of 'Accounts' Obtaining an Account
To obtain an account, you must be part of a research group which has purchased access to Hammer. Refer to the Accounts / Access page for more details on how to request access.
Link to section 'Outside Collaborators' of 'Accounts' Outside Collaborators
A valid Purdue Career Account is required for access to any resource. If you do not currently have a valid Purdue Career Account you must have a current Purdue faculty or staff member file a Request for Privileges (R4P) before you can proceed.
Logging In
To submit jobs on Hammer, log in to the submission host hammer.rcac.purdue.edu via SSH. This submission host is actually 2 front-end hosts: hammer-fe00 and hammer-fe01. The login process randomly assigns one of these front-ends to each login to hammer.rcac.purdue.edu.
Purdue Login
Link to section 'SSH' of 'Purdue Login' SSH
- SSH to the cluster as usual.
- When asked for a password, type your password followed by "
,push". - Your Purdue Duo client will receive a notification to approve the login.
Link to section 'Thinlinc' of 'Purdue Login' Thinlinc
- When asked for a password, type your password followed by "
,push". - Your Purdue Duo client will receive a notification to approve the login.
- The native Thinlinc client will prompt for Duo approval twice due to the way Thinlinc works.
- The native Thinlinc client also supports key-based authentication.
Passwords
Hammer supports either Purdue two-factor authentication (Purdue Login) or SSH keys.
SSH Client Software
Secure Shell or SSH is a way of establishing a secure connection between two computers. It uses public-key cryptography to authenticate the user with the remote computer and to establish a secure connection. Its usual function involves logging in to a remote machine and executing commands. There are many SSH clients available for all operating systems:
Linux / Solaris / AIX / HP-UX / Unix:
- The
sshcommand is pre-installed. Log in usingssh myusername@hammer.rcac.purdue.edufrom a terminal.
Microsoft Windows:
- MobaXterm is a small, easy to use, full-featured SSH client. It includes X11 support for remote displays, SFTP capabilities, and limited SSH authentication forwarding for keys.
Mac OS X:
- The
sshcommand is pre-installed. You may start a local terminal window from "Applications->Utilities". Log in by typing the commandssh myusername@hammer.rcac.purdue.edu.
When prompted for password, enter your Purdue career account password followed by ",push ". Your Purdue Duo client will then receive a notification to approve the login.
SSH Keys
Link to section 'General overview' of 'SSH Keys' General overview
To connect to Hammer using SSH keys, you must follow three high-level steps:
- Generate a key pair consisting of a private and a public key on your local machine.
- Copy the public key to the cluster and append it to
$HOME/.ssh/authorized_keysfile in your account. - Test if you can ssh from your local computer to the cluster without using your Purdue password.
Detailed steps for different operating systems and specific SSH client softwares are give below.
Link to section 'Mac and Linux:' of 'SSH Keys' Mac and Linux:
-
Run
ssh-keygenin a terminal on your local machine. You may supply a filename and a passphrase for protecting your private key, but it is not mandatory. To accept the default settings, press Enter without specifying a filename.
Note: If you do not protect your private key with a passphrase, anyone with access to your computer could SSH to your account on Hammer. -
By default, the key files will be stored in
~/.ssh/id_rsaand~/.ssh/id_rsa.pubon your local machine. -
Copy the contents of the public key into
$HOME/.ssh/authorized_keyson the cluster with the following command. When asked for a password, type your password followed by ",push". Your Purdue Duo client will receive a notification to approve the login.ssh-copy-id -i ~/.ssh/id_rsa.pub myusername@hammer.rcac.purdue.eduNote: use your actual Purdue account user name.
If your system does not have the
ssh-copy-idcommand, use this instead:cat ~/.ssh/id_rsa.pub | ssh myusername@hammer.rcac.purdue.edu "mkdir -p ~/.ssh && chmod 700 ~/.ssh && cat >> ~/.ssh/authorized_keys" -
Test the new key by SSH-ing to the server. The login should now complete without asking for a password.
-
If the private key has a non-default name or location, you need to specify the key by
ssh -i my_private_key_name myusername@hammer.rcac.purdue.edu
Link to section 'Windows:' of 'SSH Keys' Windows:
| Programs | Instructions |
|---|---|
| MobaXterm | Open a local terminal and follow Linux steps |
| Git Bash | Follow Linux steps |
| Windows 10 PowerShell | Follow Linux steps |
| Windows 10 Subsystem for Linux | Follow Linux steps |
| PuTTY | Follow steps below |
PuTTY:
-
Launch PuTTYgen, keep the default key type (RSA) and length (2048-bits) and click Generate button.
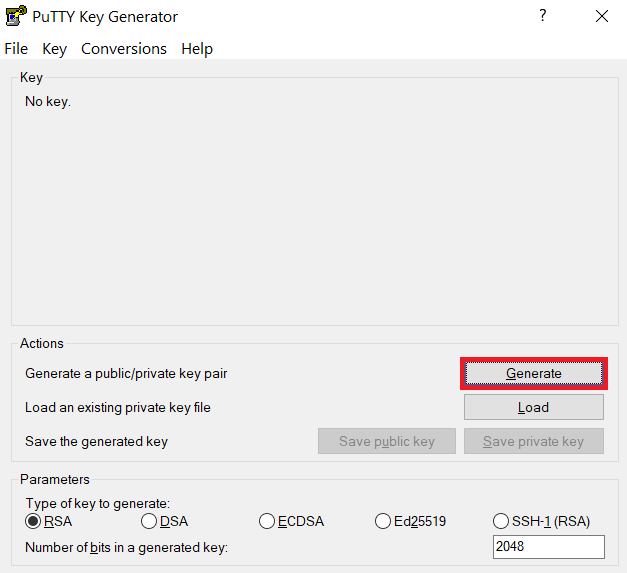
The "Generate" button can be found under the "Actions" section of the PuTTY Key Generator interface. -
Once the key pair is generated:
Use the Save public key button to save the public key, e.g.
Documents\SSH_Keys\mylaptop_public_key.pubUse the Save private key button to save the private key, e.g.
Documents\SSH_Keys\mylaptop_private_key.ppk. When saving the private key, you can also choose a reminder comment, as well as an optional passphrase to protect your key, as shown in the image below. Note: If you do not protect your private key with a passphrase, anyone with access to your computer could SSH to your account on Hammer.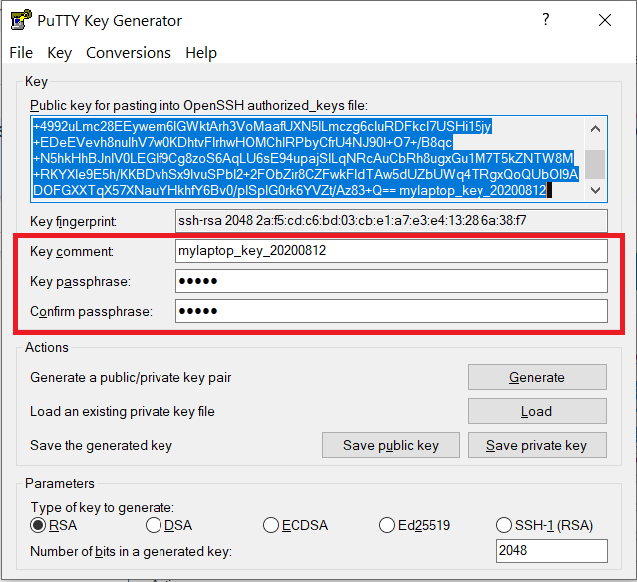
The PuTTY Key Generator form has inputs for the Key passphrase and optional reminder comment. From the menu of PuTTYgen, use the "Conversion -> Export OpenSSH key" tool to convert the private key into openssh format, e.g.
Documents\SSH_Keys\mylaptop_private_key.opensshto be used later for Thinlinc. -
Configure PuTTY to use key-based authentication:
Launch PuTTY and navigate to "Connection -> SSH ->Auth" on the left panel, click Browse button under the "Authentication parameters" section and choose your private key, e.g. mylaptop_private_key.ppk
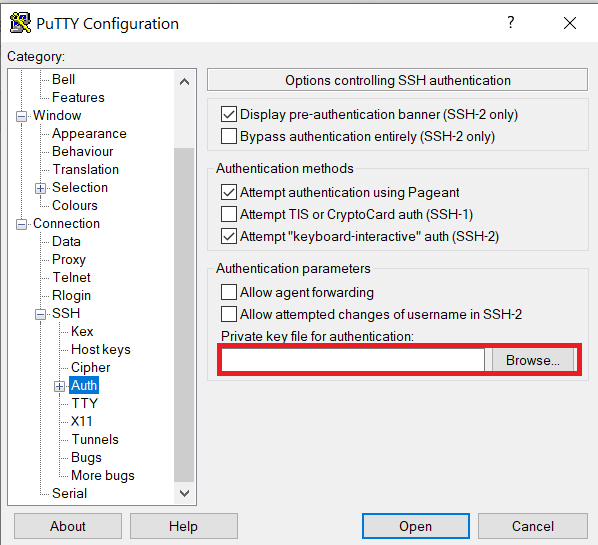
After clicking Connection -> SSH ->Auth panel, the "Browse" option can be found at the bottom of the resulting panel. Navigate back to "Session" on the left panel. Highlight "Default Settings" and click the "Save" button to ensure the change in place.
-
Connect to the cluster. When asked for a password, type your password followed by "
,push". Your Purdue Duo client will receive a notification to approve the login. Copy the contents of public key from PuTTYgen as shown below and paste it into$HOME/.ssh/authorized_keys. Please double-check that your text editor did not wrap or fold the pasted value (it should be one very long line).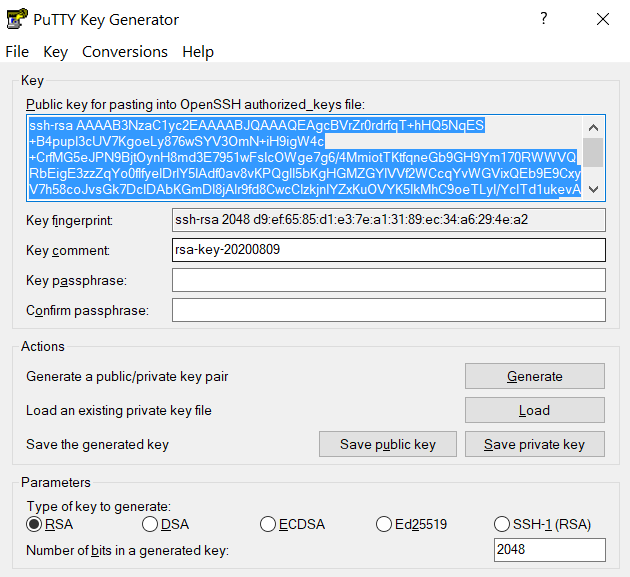
The "Public key" will look like a long string of random letters and numbers in a text box at the top of the window. - Test by connecting to the cluster. If successful, you will not be prompted for a password or receive a Duo notification. If you protected your private key with a passphrase in step 2, you will instead be prompted to enter your chosen passphrase when connecting.
SSH X11 Forwarding
SSH supports tunneling of X11 (X-Windows). If you have an X11 server running on your local machine, you may use X11 applications on remote systems and have their graphical displays appear on your local machine. These X11 connections are tunneled and encrypted automatically by your SSH client.
Link to section 'Installing an X11 Server' of 'SSH X11 Forwarding' Installing an X11 Server
To use X11, you will need to have a local X11 server running on your personal machine. Both free and commercial X11 servers are available for various operating systems.
Linux / Solaris / AIX / HP-UX / Unix:
- An X11 server is at the core of all graphical sessions. If you are logged in to a graphical environment on these operating systems, you are already running an X11 server.
- ThinLinc is an alternative to running an X11 server directly on your Linux computer. ThinLinc is a service that allows you to connect to a persistent remote graphical desktop session.
Microsoft Windows:
- ThinLinc is an alternative to running an X11 server directly on your Windows computer. ThinLinc is a service that allows you to connect to a persistent remote graphical desktop session.
- MobaXterm is a small, easy to use, full-featured SSH client. It includes X11 support for remote displays, SFTP capabilities, and limited SSH authentication forwarding for keys.
Mac OS X:
- X11 is available as an optional install on the Mac OS X install disks prior to 10.7/Lion. Run the installer, select the X11 option, and follow the instructions. For 10.7+ please download XQuartz.
- ThinLinc is an alternative to running an X11 server directly on your Mac computer. ThinLinc is a service that allows you to connect to a persistent remote graphical desktop session.
Link to section 'Enabling X11 Forwarding in your SSH Client' of 'SSH X11 Forwarding' Enabling X11 Forwarding in your SSH Client
Once you are running an X11 server, you will need to enable X11 forwarding/tunneling in your SSH client:
ssh: X11 tunneling should be enabled by default. To be certain it is enabled, you may usessh -Y.- MobaXterm: Select "New session" and "SSH." Under "Advanced SSH Settings" check the box for X11 Forwarding.
SSH will set the remote environment variable $DISPLAY to "localhost:XX.YY" when this is working correctly. If you had previously set your $DISPLAY environment variable to your local IP or hostname, you must remove any set/export/setenv of this variable from your login scripts. The environment variable $DISPLAY must be left as SSH sets it, which is to a random local port address. Setting $DISPLAY to an IP or hostname will not work.
ThinLinc
RCAC provides Cendio's ThinLinc as an alternative to running an X11 server directly on your computer. It allows you to run graphical applications or graphical interactive jobs directly on Hammer through a persistent remote graphical desktop session.
ThinLinc is a service that allows you to connect to a persistent remote graphical desktop session. This service works very well over a high latency, low bandwidth, or off-campus connection compared to running an X11 server locally. It is also very helpful for Windows users who do not have an easy to use local X11 server, as little to no set up is required on your computer.
There are two ways in which to use ThinLinc: preferably through the native client or through a web browser.
Link to section 'Installing the ThinLinc native client' of 'ThinLinc' Installing the ThinLinc native client
The native ThinLinc client will offer the best experience especially over off-campus connections and is the recommended method for using ThinLinc. It is compatible with Windows, Mac OS X, and Linux.
- Download the ThinLinc client from the ThinLinc website.
- Start the ThinLinc client on your computer.
- In the client's login window, use desktop.hammer.rcac.purdue.edu as the Server. Use your Purdue Career Account username and password, but append "
,push" to your password. - Click the Connect button.
- Your Purdue Login Duo will receive a notification to approve your login.
- Continue to following section on connecting to Hammer from ThinLinc.
Link to section 'Using ThinLinc through your web browser' of 'ThinLinc' Using ThinLinc through your web browser
The ThinLinc service can be accessed from your web browser as a convenience to installing the native client. This option works with no set up and is a good option for those on computers where you do not have privileges to install software. All that is required is an up-to-date web browser. Older versions of Internet Explorer may not work.
- Open a web browser and navigate to desktop.hammer.rcac.purdue.edu.
- Log in with your Purdue Career Account username and password, but append "
,push" to your password. - You may safely proceed past any warning messages from your browser.
- Your Purdue Login Duo will receive a notification to approve your login.
- Continue to the following section on connecting to Hammer from ThinLinc.
Link to section 'Connecting to Hammer from ThinLinc' of 'ThinLinc' Connecting to Hammer from ThinLinc
- Once logged in, you will be presented with a remote Linux desktop running directly on a cluster front-end.
- Open the terminal application on the remote desktop.
- Once logged in to the Hammer head node, you may use graphical editors, debuggers, software like Matlab, or run graphical interactive jobs. For example, to test the X forwarding connection issue the following command to launch the graphical editor gedit:
$ gedit - This session will remain persistent even if you disconnect from the session. Any interactive jobs or applications you left running will continue running even if you are not connected to the session.
Link to section 'Tips for using ThinLinc native client' of 'ThinLinc' Tips for using ThinLinc native client
- To exit a full screen ThinLinc session press the F8 key on your keyboard (fn + F8 key for Mac users) and click to disconnect or exit full screen.
- Full screen mode can be disabled when connecting to a session by clicking the Options button and disabling full screen mode from the Screen tab.
Link to section 'Configure ThinLinc to use SSH Keys' of 'ThinLinc' Configure ThinLinc to use SSH Keys
- The web client does NOT support public-key authentication.
-
ThinLinc native client supports the use of an SSH key pair. For help generating and uploading keys to the cluster, see SSH Keys section in our user guide for details.
To set up SSH key authentication on the ThinLinc client:
-
Open the Options panel, and select Public key as your authentication method on the Security tab.
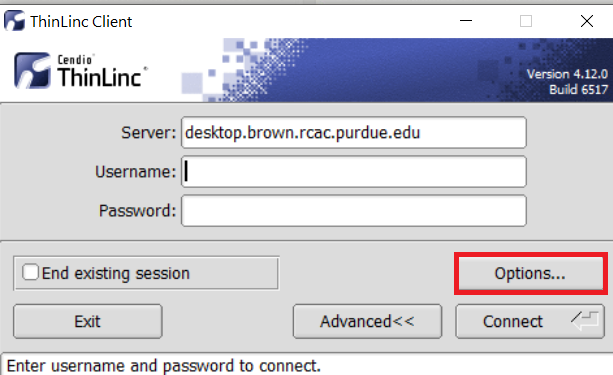
The "Options..." button in the ThinLinc Client can be found towards the bottom left, above the "Connect" button. -
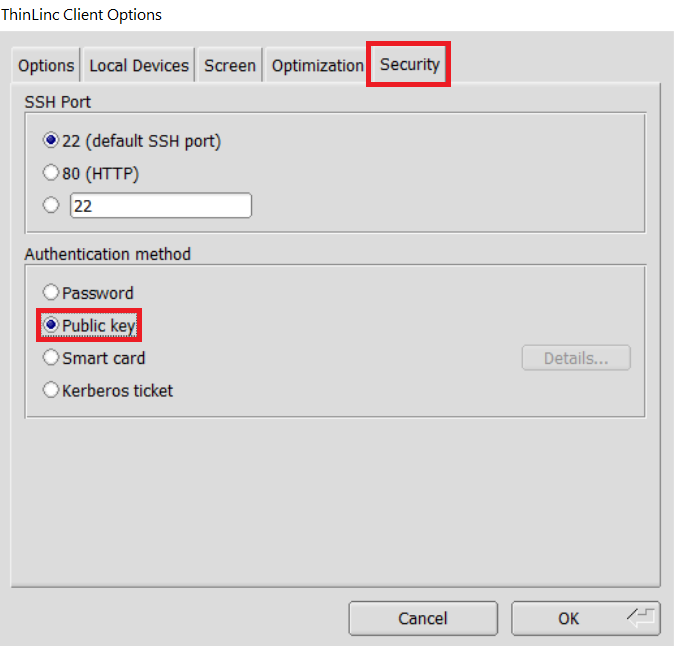
In the options dialog, switch to the "Security" tab and select the "Public key" radio button:
The "Security" tab found in the options dialog, will be the last of available tabs. The "Public key" option can be found in the "Authentication method" options group. - Click OK to return to the ThinLinc Client login window. You should now see a Key field in place of the Password field.
-
In the Key field, type the path to your locally stored private key or click the ... button to locate and select the key on your local system. Note: If PuTTY is used to generate the SSH Key pairs, please choose the private key in the openssh format.
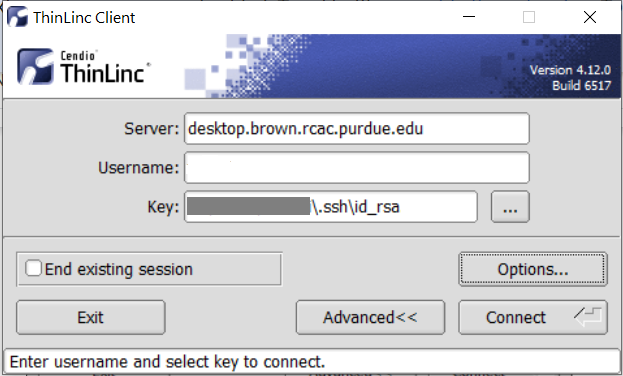
The ThinLinc Client login window will now display key field instead of a password field.
-
Purchasing Nodes
RCAC operates a significant shared cluster computing infrastructure developed over several years through focused acquisitions using funds from grants, faculty startup packages, and institutional sources. These "community clusters" are now at the foundation of Purdue's research cyberinfrastructure.
We strongly encourage any Purdue faculty or staff with computational needs to join this growing community and enjoy the enormous benefits this shared infrastructure provides:
- Peace of Mind
RCAC system administrators take care of security patches, attempted hacks, operating system upgrades, and hardware repair so faculty and graduate students can concentrate on research.
- Low Overhead
RCAC data centers provide infrastructure such as networking, racks, floor space, cooling, and power.
- Cost Effective
RCAC works with vendors to obtain the best price for computing resources by pooling funds from different disciplines to leverage greater group purchasing power.
Through the Community Cluster Program, Purdue affiliates have invested several million dollars in computational and storage resources from Q4 2006 to the present with great success in both the research accomplished and the money saved on equipment purchases.
For more information or to purchase access to our latest cluster today, see the Purchase page. Have questions? contact us at rcac-cluster-purchase@lists.purdue.edu to discuss.
File Storage and Transfer
Learn more about file storage transfer for Hammer.
Link to section 'Archive and Compression' of 'Archive and Compression' Archive and Compression
There are several options for archiving and compressing groups of files or directories. The mostly commonly used options are:
Link to section 'tar' of 'Archive and Compression' tar
See the official documentation for tar for more information.
Saves many files together into a single archive file, and restores individual files from the archive. Includes automatic archive compression/decompression options and special features for incremental and full backups.
Examples:
(list contents of archive somefile.tar)
$ tar tvf somefile.tar
(extract contents of somefile.tar)
$ tar xvf somefile.tar
(extract contents of gzipped archive somefile.tar.gz)
$ tar xzvf somefile.tar.gz
(extract contents of bzip2 archive somefile.tar.bz2)
$ tar xjvf somefile.tar.bz2
(archive all ".c" files in current directory into one archive file)
$ tar cvf somefile.tar *.c
(archive and gzip-compress all files in a directory into one archive file)
$ tar czvf somefile.tar.gz somedirectory/
(archive and bzip2-compress all files in a directory into one archive file)
$ tar cjvf somefile.tar.bz2 somedirectory/
Other arguments for tar can be explored by using the man tar command.
Link to section 'gzip' of 'Archive and Compression' gzip
The standard compression system for all GNU software.
Examples:
(compress file somefile - also removes uncompressed file)
$ gzip somefile
(uncompress file somefile.gz - also removes compressed file)
$ gunzip somefile.gz
Link to section 'bzip2' of 'Archive and Compression' bzip2
See the official documentation for bzip for more information.
Strong, lossless data compressor based on the Burrows-Wheeler transform. Stronger compression than gzip.
Examples:
(compress file somefile - also removes uncompressed file)
$ bzip2 somefile
(uncompress file somefile.bz2 - also removes compressed file)
$ bunzip2 somefile.bz2
There are several other, less commonly used, options available as well:
- zip
- 7zip
- xz
Link to section 'Environment Variables' of 'Environment Variables' Environment Variables
Several environment variables are automatically defined for you to help you manage your storage. Use environment variables instead of actual paths whenever possible to avoid problems if the specific paths to any of these change.
| Name | Description |
|---|---|
| HOME | /home/myusername |
| PWD | path to your current directory |
| RCAC_SCRATCH | /scratch/hammer/myusername |
By convention, environment variable names are all uppercase. You may use them on the command line or in any scripts in place of and in combination with hard-coded values:
$ ls $HOME
...
$ ls $RCAC_SCRATCH/myproject
...
To find the value of any environment variable:
$ echo $RCAC_SCRATCH
${resource.scratch}/m/myusername
To list the values of all environment variables:
$ env
USER=myusername
HOME=/home/myusername
RCAC_SCRATCH=${resource.scratch}/m/myusername
...
You may create or overwrite an environment variable. To pass (export) the value of a variable in bash:
$ export MYPROJECT=$RCAC_SCRATCH/myproject
To assign a value to an environment variable in either tcsh or csh:
$ setenv MYPROJECT value
Storage Options
File storage options on RCAC systems include long-term storage (home directories, depot, Fortress) and short-term storage (scratch directories, /tmp directory). Each option has different performance and intended uses, and some options vary from system to system as well. Daily snapshots of home directories are provided for a limited time for accidental deletion recovery. Scratch directories and temporary storage are not backed up and old files are regularly purged from scratch and /tmp directories. More details about each storage option appear below.
Home Directory
Home directories are provided for long-term file storage. Each user has one home directory. You should use your home directory for storing important program files, scripts, input data sets, critical results, and frequently used files. You should store infrequently used files on Fortress. Your home directory becomes your current working directory, by default, when you log in.
Daily snapshots of your home directory are provided for a limited period of time in the event of accidental deletion. For additional security, you should store another copy of your files on more permanent storage, such as the Fortress HPSS Archive.
Your home directory physically resides on a GPFS storage system in the data center. To find the path to your home directory, first log in then immediately enter the following:
$ pwd
/home/myusername
Or from any subdirectory:
$ echo $HOME
/home/myusername
Your home directory has a quota limiting the total size of files you may store within. For more information, refer to the Storage Quotas / Limits Section.
Link to section 'Lost File Recovery' of 'Home Directory' Lost File Recovery
Nightly snapshots for 7 days, weekly snapshots for 4 weeks, and monthly snapshots for 3 months are kept. This means you will find snapshots from the last 7 nights, the last 4 Sundays, and the last 3 first of the months. Files are available going back between two and three months, depending on how long ago the last first of the month was. Snapshots beyond this are not kept. For additional security, you should store another copy of your files on more permanent storage, such as the Fortress HPSS Archive.
Link to section 'Performance' of 'Home Directory' Performance
Your home directory is medium-performance, non-purged space suitable for tasks like sharing data, editing files, developing and building software, and many other uses.
Your home directory is not designed or intended for use as high-performance working space for running data-intensive jobs with heavy I/O demands.
Link to section 'Long-Term Storage' of 'Long-Term Storage' Long-Term Storage
Long-term Storage or Permanent Storage is available to users on the High Performance Storage System (HPSS), an archival storage system, called Fortress. Program files, data files and any other files which are not used often, but which must be saved, can be put in permanent storage. Fortress currently has over 10PB of capacity.
For more information about Fortress, how it works, and user guides, and how to obtain an account:
Scratch Space
Scratch directories are provided for short-term file storage only. The quota of your scratch directory is much greater than the quota of your home directory. You should use your scratch directory for storing temporary input files which your job reads or for writing temporary output files which you may examine after execution of your job. You should use your home directory and Fortress for longer-term storage or for holding critical results. The hsi and htar commands provide easy-to-use interfaces into the archive and can be used to copy files into the archive interactively or even automatically at the end of your regular job submission scripts.
Files in scratch directories are not recoverable. Files in scratch directories are not backed up. If you accidentally delete a file, a disk crashes, or old files are purged, they cannot be restored.
Files are purged from scratch directories not accessed or had content modified in 60 days. Owners of these files receive a notice one week before removal via email. Be sure to regularly check your Purdue email account or set up mail forwarding to an email account you do regularly check. For more information, please refer to our Scratch File Purging Policy.
All users may access scratch directories on Hammer. To find the path to your scratch directory:
$ findscratch
${resource.scratch}/m/myusername
The value of variable $RCAC_SCRATCH is your scratch directory path. Use this variable in any scripts. Your actual scratch directory path may change without warning, but this variable will remain current.
$ echo $RCAC_SCRATCH
${resource.scratch}/m/myusername
Scratch directories are specific per cluster. I.e. only the ${resource.scratch} directory is available on Hammer front-end and compute nodes. No other scratch directories are available on Hammer.
Your scratch directory has a quota capping the total size and number of files you may store in it. For more information, refer to the section Storage Quotas / Limits.
Link to section 'Performance' of 'Scratch Space' Performance
Your scratch directory is located on a high-performance, large-capacity parallel filesystem engineered to provide work-area storage optimized for a wide variety of job types. It is designed to perform well with data-intensive computations, while scaling well to large numbers of simultaneous connections.
/tmp Directory
/tmp directories are provided for short-term file storage only. Each front-end and compute node has a /tmp directory. Your program may write temporary data to the /tmp directory of the compute node on which it is running. That data is available for as long as your program is active. Once your program terminates, that temporary data is no longer available. When used properly, /tmp may provide faster local storage to an active process than any other storage option. You should use your home directory and Fortress for longer-term storage or for holding critical results.
Backups are not performed for the /tmp directory and removes files from /tmp whenever space is low or whenever the system needs a reboot. In the event of a disk crash or file purge, files in /tmp are not recoverable. You should copy any important files to more permanent storage.
Storage Quota / Limits
Some limits are imposed on your disk usage on research systems. A quota is implemented on each filesystem. Each filesystem (home directory, scratch directory, etc.) may have a different limit. If you exceed the quota, you will not be able to save new files or new data to the filesystem until you delete or move data to long-term storage.
Link to section 'Checking Quota' of 'Storage Quota / Limits' Checking Quota
To check the current quotas of your home and scratch directories check the My Quota page or use the myquota command:
$ myquota
Type Filesystem Size Limit Use Files Limit Use
==============================================================================
home myusername 5.0GB 25.0GB 20% - - -
scratch hammer 220.7GB 100.0TB 0.22% 8k 2,000k 0.43%
The columns are as follows:
- Type: indicates home or scratch directory.
- Filesystem: name of storage option.
- Size: sum of file sizes in bytes.
- Limit: allowed maximum on sum of file sizes in bytes.
- Use: percentage of file-size limit currently in use.
- Files: number of files and directories (not the size).
- Limit: allowed maximum on number of files and directories. It is possible, though unlikely, to reach this limit and not the file-size limit if you create a large number of very small files.
- Use: percentage of file-number limit currently in use.
If you find that you reached your quota in either your home directory or your scratch file directory, obtain estimates of your disk usage. Find the top-level directories which have a high disk usage, then study the subdirectories to discover where the heaviest usage lies.
To see in a human-readable format an estimate of the disk usage of your top-level directories in your home directory:
$ du -h --max-depth=1 $HOME >myfile
32K /home/myusername/mysubdirectory_1
529M /home/myusername/mysubdirectory_2
608K /home/myusername/mysubdirectory_3
The second directory is the largest of the three, so apply command du to it.
To see in a human-readable format an estimate of the disk usage of your top-level directories in your scratch file directory:
$ du -h --max-depth=1 $RCAC_SCRATCH >myfile
K ${resource.scratch}/m/myusername
This strategy can be very helpful in figuring out the location of your largest usage. Move unneeded files and directories to long-term storage to free space in your home and scratch directories.
Link to section 'Increasing Quota' of 'Storage Quota / Limits' Increasing Quota
Link to section 'Home Directory' of 'Storage Quota / Limits' Home Directory
If you find you need additional disk space in your home directory, please first consider archiving and compressing old files and moving them to long-term storage on the Fortress HPSS Archive. Unfortunately, it is not possible to increase your home directory quota beyond it's current level.
Link to section 'Scratch Space' of 'Storage Quota / Limits' Scratch Space
If you find you need additional disk space in your scratch space, please first consider archiving and compressing old files and moving them to long-term storage on the Fortress HPSS Archive. If you are unable to do so, you may ask for a quota increase by contacting support.
Link to section 'Sharing Files from Hammer' of 'Sharing' Sharing Files from Hammer
Hammer supports several methods for file sharing. Use the links below to learn more about these methods.
Link to section 'Sharing Data with Globus' of 'Globus' Sharing Data with Globus
Data on any RCAC resource can be shared with other users within Purdue or with collaborators at other institutions. Globus allows convenient sharing of data with outside collaborators. Data can be shared with collaborators' personal computers or directly with many other computing resources at other institutions.
To share files, login to https://transfer.rcac.purdue.edu, navigate to the endpoint (collection) of your choice, and follow instructions as described in Globus documentation on how to share data:
See also RCAC Globus presentation.
File Transfer
Hammer supports several methods for file transfer. Use the links below to learn more about these methods.
SCP
SCP (Secure CoPy) is a simple way of transferring files between two machines that use the SSH protocol. SCP is available as a protocol choice in some graphical file transfer programs and also as a command line program on most Linux, Unix, and Mac OS X systems. SCP can copy single files, but will also recursively copy directory contents if given a directory name.
After Aug 17, 2020, the community clusters will not support password-based authentication for login. Methods that can be used include two-factor authentication (Purdue Login) or SSH keys. If you do not have SSH keys installed, you would need to type your Purdue Login response into the SFTP's "Password" prompt.
Link to section 'Command-line usage:' of 'SCP' Command-line usage:
You can transfer files both to and from Hammer while initiating an SCP session on either some other computer or on Hammer (in other words, directionality of connection and directionality of data flow are independent from each other). The scp command appears somewhat similar to the familiar cp command, with an extra user@host:file syntax to denote files and directories on a remote host. Either Hammer or another computer can be a remote.
Example: Initiating SCP session on some other computer (i.e. you are on some other computer, connecting to Hammer):
(transfer TO Hammer) (Individual files) $ scp sourcefile myusername@hammer.rcac.purdue.edu:somedir/destinationfile $ scp sourcefile myusername@hammer.rcac.purdue.edu:somedir/ (Recursive directory copy) $ scp -pr sourcedirectory/ myusername@hammer.rcac.purdue.edu:somedir/ (transfer FROM Hammer) (Individual files) $ scp myusername@hammer.rcac.purdue.edu:somedir/sourcefile destinationfile $ scp myusername@hammer.rcac.purdue.edu:somedir/sourcefile somedir/ (Recursive directory copy) $ scp -pr myusername@hammer.rcac.purdue.edu:sourcedirectory somedir/The -p flag is optional. When used, it will cause the transfer to preserve file attributes and permissions. The -r flag is required for recursive transfers of entire directories.
Example: Initiating SCP session on Hammer (i.e. you are on Hammer, connecting to some other computer):
(transfer TO Hammer) (Individual files) $ scp myusername@$another.computer.example.com:sourcefile somedir/destinationfile $ scp myusername@$another.computer.example.com:sourcefile somedir/ (Recursive directory copy) $ scp -pr myusername@$another.computer.example.com:sourcedirectory/ somedir/ (transfer FROM Hammer) (Individual files) $ scp somedir/sourcefile myusername@$another.computer.example.com:destinationfile $ scp somedir/sourcefile myusername@$another.computer.example.com:somedir/ (Recursive directory copy) $ scp -pr sourcedirectory myusername@$another.computer.example.com:somedir/The -p flag is optional. When used, it will cause the transfer to preserve file attributes and permissions. The -r flag is required for recursive transfers of entire directories.
Link to section 'Software (SCP clients)' of 'SCP' Software (SCP clients)
Linux and other Unix-like systems:
- The
scpcommand-line program should already be installed.
Microsoft Windows:
- MobaXterm
Free, full-featured, graphical Windows SSH, SCP, and SFTP client. - Command-line
scpprogram can be installed as part of Windows Subsystem for Linux (WSL), or Git-Bash.
Mac OS X:
- The
scpcommand-line program should already be installed. You may start a local terminal window from "Applications->Utilities". - Cyberduck is a full-featured and free graphical SFTP and SCP client.
Globus
Globus, previously known as Globus Online, is a powerful and easy to use file transfer service for transferring files virtually anywhere. It works within RCAC's various research storage systems; it connects between RCAC and remote research sites running Globus; and it connects research systems to personal systems. You may use Globus to connect to your home, scratch, and Fortress storage directories. Since Globus is web-based, it works on any operating system that is connected to the internet. The Globus Personal client is available on Windows, Linux, and Mac OS X. It is primarily used as a graphical means of transfer but it can also be used over the command line.
Link to section 'Globus Web:' of 'Globus' Globus Web:
- Navigate to http://transfer.rcac.purdue.edu
- Click "Proceed" to log in with your Purdue Career Account.
- On your first login it will ask to make a connection to a Globus account. Accept the conditions.
- Now you are at the main screen. Click "File Transfer" which will bring you to a two-panel interface (if you only see one panel, you can use selector in the top-right corner to switch the view).
- You will need to select one collection and file path on one side as the source, and the second collection on the other as the destination. This can be one of several Purdue endpoints, or another University, or even your personal computer (see Personal Client section below).
The RCAC collections are as follows. A search for "Purdue" will give you several suggested results you can choose from, or you can give a more specific search.
- Home Directory storage: "Purdue Research Computing - Home Directories", however, you can start typing "Purdue" and "Home Directories" and it will suggest appropriate matches.
- Hammer scratch storage: "Purdue Hammer Cluster", however, you can start typing "Purdue" and "Hammer and it will suggest appropriate matches. From here you will need to navigate into the first letter of your username, and then into your username.
- Research Data Depot: "Purdue Research Computing - Data Depot", a search for "Depot" should provide appropriate matches to choose from.
- Fortress: "Purdue Fortress HPSS Archive", a search for "Fortress" should provide appropriate matches to choose from.
From here, select a file or folder in either side of the two-pane window, and then use the arrows in the top-middle of the interface to instruct Globus to move files from one side to the other. You can transfer files in either direction. You will receive an email once the transfer is completed.
Link to section 'Globus Personal Client setup:' of 'Globus' Globus Personal Client setup:
Globus Connect Personal is a small software tool you can install to make your own computer a Globus endpoint on its own. It is useful if you need to transfer files via Globus to and from your computer directly.
- On the "Collections" page from earlier, click "Get Globus Connect Personal" or download a version for your operating system it from here: Globus Connect Personal
- Name this particular personal system and follow the setup prompts to create your Globus Connect Personal endpoint.
- Your personal system is now available as a collection within the Globus transfer interface.
Link to section 'Globus Command Line:' of 'Globus' Globus Command Line:
Globus supports command line interface, allowing advanced automation of your transfers.
To use the recommended standalone Globus CLI application (the globus command):
- First time use: issue the globus login command and follow instructions for initial login.
- Commands for interfacing with the CLI can be found via Using the Command Line Interface, as well as the Globus CLI Examples pages.
Link to section 'Sharing Data with Outside Collaborators' of 'Globus' Sharing Data with Outside Collaborators
Globus allows convenient sharing of data with outside collaborators. Data can be shared with collaborators' personal computers or directly with many other computing resources at other institutions. See the Globus documentation on how to share data:
For links to more information, please see Globus Support page and RCAC Globus presentation.
Windows Network Drive / SMB
SMB (Server Message Block), also known as CIFS, is an easy to use file transfer protocol that is useful for transferring files between RCAC systems and a desktop or laptop. You may use SMB to connect to your home, scratch, and Fortress storage directories. The SMB protocol is available on Windows, Linux, and Mac OS X. It is primarily used as a graphical means of transfer but it can also be used over the command line.
Note: to access Hammer through SMB file sharing, you must be on a Purdue campus network or connected through VPN.
Link to section 'Windows:' of 'Windows Network Drive / SMB' Windows:
- Windows 7: Click Windows menu > Computer, then click Map Network Drive in the top bar
- Windows 8 & 10: Tap the Windows key, type computer, select This PC, click Computer > Map Network Drive in the top bar
- In the folder location enter the following information and click Finish:
- To access your home directory, enter \\home.rcac.purdue.edu\myusername.
- Note: Use your career account login name and password when prompted. (You will not need to add "
,push" nor use your Purdue Duo client.)
- Your home directory should now be mounted as a drive in the Computer window.
Link to section 'Mac OS X:' of 'Windows Network Drive / SMB' Mac OS X:
- In the Finder, click Go > Connect to Server
- In the Server Address enter the following information and click Connect:
- To access your home directory, enter smb://home.rcac.purdue.edu/myusername.
- Note: Use your career account login name and password when prompted. (You will not need to add "
,push" nor use your Purdue Duo client.)
Link to section 'Linux:' of 'Windows Network Drive / SMB' Linux:
- There are several graphical methods to connect in Linux depending on your desktop environment. Once you find out how to connect to a network server on your desktop environment, choose the Samba/SMB protocol and adapt the information from the Mac OS X section to connect.
- If you would like access via samba on the command line you may install smbclient which will give you FTP-like access and can be used as shown below. For all the possible ways to connect look at the Mac OS X instructions.
smbclient //home.rcac.purdue.edu/myusername -U myusername - Note: Use your career account login name and password when prompted. (You will not need to add "
,push" nor use your Purdue Duo client.)
FTP / SFTP
FTP is not supported on any research systems because it does not allow for secure transmission of data. Use SFTP instead, as described below.
SFTP (Secure File Transfer Protocol) is a reliable way of transferring files between two machines. SFTP is available as a protocol choice in some graphical file transfer programs and also as a command-line program on most Linux, Unix, and Mac OS X systems. SFTP has more features than SCP and allows for other operations on remote files, remote directory listing, and resuming interrupted transfers. Command-line SFTP cannot recursively copy directory contents; to do so, try using SCP or graphical SFTP client.
After Aug 17, 2020, the community clusters will not support password-based authentication for login. Methods that can be used include two-factor authentication (Purdue Login) or SSH keys. If you do not have SSH keys installed, you would need to type your Purdue Login response into the SFTP's "Password" prompt.
Link to section 'Command-line usage' of 'FTP / SFTP' Command-line usage
You can transfer files both to and from Hammer while initiating an SFTP session on either some other computer or on Hammer (in other words, directionality of connection and directionality of data flow are independent from each other). Once the connection is established, you use put or get subcommands between "local" and "remote" computers. Either Hammer or another computer can be a remote.
Example: Initiating SFTP session on some other computer (i.e. you are on another computer, connecting to Hammer):
$ sftp myusername@hammer.rcac.purdue.edu (transfer TO Hammer) sftp> put sourcefile somedir/destinationfile sftp> put -P sourcefile somedir/ (transfer FROM Hammer) sftp> get sourcefile somedir/destinationfile sftp> get -P sourcefile somedir/ sftp> exitThe -P flag is optional. When used, it will cause the transfer to preserve file attributes and permissions.
Example: Initiating SFTP session on Hammer (i.e. you are on Hammer, connecting to some other computer):
$ sftp myusername@$another.computer.example.com (transfer TO Hammer) sftp> get sourcefile somedir/destinationfile sftp> get -P sourcefile somedir/ (transfer FROM Hammer) sftp> put sourcefile somedir/destinationfile sftp> put -P sourcefile somedir/ sftp> exitThe -P flag is optional. When used, it will cause the transfer to preserve file attributes and permissions.
Link to section 'Software (SFTP clients)' of 'FTP / SFTP' Software (SFTP clients)
Linux and other Unix-like systems:
- The
sftpcommand-line program should already be installed.
Microsoft Windows:
- MobaXterm
Free, full-featured, graphical Windows SSH, SCP, and SFTP client. - Command-line
sftpprogram can be installed as part of Windows Subsystem for Linux (WSL), or Git-Bash.
Mac OS X:
- The
sftpcommand-line program should already be installed. You may start a local terminal window from "Applications->Utilities". - Cyberduck is a full-featured and free graphical SFTP and SCP client.
Software
Link to section 'Environment module' of 'Software' Environment module
Link to section 'Software catalog' of 'Software' Software catalog
Environment Management with the Module Command
Our clusters provide a number of software packages to users of the system via the module command.
Link to section 'Environment Management with the Module Command' of 'Environment Management with the Module Command' Environment Management with the Module Command
The module command is the preferred method to manage your processing environment. With this command, you may load applications and compilers along with their libraries and paths. Modules are packages which you load and unload as needed.
Please use the module command and do not manually configure your environment, as staff may make changes to the specifics of various packages. If you use the module command to manage your environment, these changes will not be noticeable.
Link to section 'Hierarchy' of 'Environment Management with the Module Command' Hierarchy
Many modules have dependencies on other modules. For example, a particular openmpi module requires a specific version of the Intel compiler to be loaded. Often, these dependencies are not clear for users of the module, and there are many modules which may conflict. Arranging modules in an hierarchical fashion makes this dependency clear. This arrangement also helps make the software stack easy to understand - your view of the modules will not be cluttered with a bunch of conflicting packages.
Your default module view on Hammer will include a set of compilers and the set of basic software that has no dependencies (such as Matlab and Fluent). To make software available that depends on a compiler, you must first load the compiler, and then software which depends on it becomes available to you. In this way, all software you see when doing "module avail" is completely compatible with each other.
Link to section 'Using the Hierarchy' of 'Environment Management with the Module Command' Using the Hierarchy
Your default module view on Hammer will include a set of compilers, and the set of basic software that has no dependencies (such as Matlab and Fluent).
To see what modules are available on this system by default:
$ module avail
To see which versions of a specific compiler are available on this system:
$ module avail gcc
$ module avail intel
To continue further into the hierarchy of modules, you will need to choose a compiler. As an example, if you are planning on using the Intel compiler you will first want to load the Intel compiler:
$ module load intel
With intel loaded, you can repeat the avail command and at the bottom of the output you will see the a section of additional software that the intel module provides:
$ module avail
Several of these new packages also provide additional software packages, such as MPI libraries. You can repeat the last two steps with one of the MPI packages such as openmpi and you will have a few more software packages available to you.
If you are looking for a specific software package and do not see it in your default view, the module command provides a search function for searching the entire hierarchy tree of modules without need for you to manually load and avail on every module.
To search for a software package:
$ module spider openmpi
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
openmpi:
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Versions:
openmpi/2.1.6
openmpi/3.1.4
openmpi/3.1.6
openmpi/4.0.5
openmpi/4.1.3
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
For detailed information about a specific "openmpi" package (including how to load the modules) use the module's full name.
Note that names that have a trailing (E) are extensions provided by other modules.
For example:
$ module spider openmpi/4.1.3
This will search for the openmpi software package. If you do not specify a specific version of the package, you will be given a list of versions available on the system. Select the version you wish to use and spider that to see how to access the module:
$ module spider openmpi/4.1.3
...
You will need to load all module(s) on any one of the lines below before the "openmpi/4.1.3" module is available to load.
aocc/2.1.0
gcc/10.2.0
gcc/4.8.5
gcc/6.3.0
gcc/9.3.0
intel/17.0.1.132
intel/19.0.5.281
...
The output of this command will instruct you that you can load the this module directly, or in case of the above example, that you will need to first load a module or two. With the information provide with this command, you can now construct a load command to load a version of OpenMPI into your environment:
$ module load intel/19.0.5.281 openmpi/4.1.3
Some user communities may maintain copies of their domain software for others to use. For example, the Purdue Bioinformatics Core provides a wide set of bioinformatics software for use by any user of RCAC clusters via the bioinfo module. The spider command will also search this repository of modules. If it finds a software package available in the bioinfo module repository, the spider command will instruct you to load the bioinfo module first.
Link to section 'Load / Unload a Module' of 'Environment Management with the Module Command' Load / Unload a Module
All modules consist of both a name and a version number. When loading a module, you may use only the name to load the default version, or you may specify which version you wish to load.
For each cluster, RCAC makes a recommendation regarding the set of compiler, math library, and MPI library for parallel code. To load the recommended set:
$ module load rcac
To verify what you loaded:
$ module list
To load the default version of a specific compiler, choose one of the following commands:
$ module load gcc
$ module load intel
To load a specific version of a compiler, include the version number:
$ module load gcc/11.2.0
When running a job, you must use the job submission file to load on the compute node(s) any relevant modules. Loading modules on the front end before submitting your job makes the software available to your session on the front-end, but not to your job submission script environment. You must load the necessary modules in your job submission script.
To unload a compiler or software package you loaded previously:
$ module unload gcc
$ module unload intel
$ module unload matlab
To unload all currently loaded modules and reset your environment:
$ module purge
Link to section 'Show Module Details' of 'Environment Management with the Module Command' Show Module Details
To learn more about what a module does to your environment, you may use the module show command. Here is an example showing what loading the default Matlab does to the processing environment:
-------------------------------------------------------------------------------------------------------------------------------------------
/opt/spack/modulefiles/Core/matlab/R2022a.lua:
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
whatis("Name : matlab")
whatis("Version : R2022a")
...
setenv("MATLAB_HOME","/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa")
setenv("RCAC_MATLAB_ROOT","/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa")
setenv("RCAC_MATLAB_VERSION","R2022a")
setenv("MATLAB","/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa")
setenv("MLROOT","/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa")
setenv("ARCH","glnxa64")
append_path("PATH","/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa/bin/glnxa64:/apps/spack/hammer/apps/matlab/R2019a-gcc-4.8.5-jg35hvf/bin")
append_path("CMAKE_PREFIX_PATH","/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa/")
append_path("LD_LIBRARY_PATH","/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa/runtime/glnxa64:/apps/spack/hammer/apps/matlab/R2022a-gcc-8.5.0-u54n6sa/bin/glnxa64")
Compiling Source Code
Documentation on compiling source code on Hammer.
Compiling Serial Programs
A serial program is a single process which executes as a sequential stream of instructions on one processor core. Compilers capable of serial programming are available for C, C++, and versions of Fortran.
Here are a few sample serial programs:
- serial_hello.f
- serial_hello.f90
- serial_hello.f95
- serial_hello.c
-
To load a compiler, enter one of the following:
$ module load intel
$ module load gcc| Language | Intel Compiler | GNU Compiler | |
|---|---|---|---|
| Fortran 77 | |
|
|
| Fortran 90 | |
|
|
| Fortran 95 | |
|
|
| C | |
|
|
| C++ | |
|
The Intel and GNU compilers will not output anything for a successful compilation. Also, the Intel compiler does not recognize the suffix ".f95".
Compiling OpenMP Programs
All compilers installed on Brown include OpenMP functionality for C, C++, and Fortran. An OpenMP program is a single process that takes advantage of a multi-core processor and its shared memory to achieve a form of parallel computing called multithreading. It distributes the work of a process over processor cores in a single compute node without the need for MPI communications.
| Language | Header Files |
|---|---|
| Fortran 77 | |
| Fortran 90 | |
| Fortran 95 | |
| C | |
| C++ | |
Sample programs illustrate task parallelism of OpenMP:
A sample program illustrates loop-level (data) parallelism of OpenMP:
To load a compiler, enter one of the following:
$ module load intel
$ module load gcc| Language | Intel Compiler | GNU Compiler |
|---|---|---|
| Fortran 77 | |
|
| Fortran 90 | |
|
| Fortran 95 | |
|
| C | |
|
| C++ | |
|
The Intel and GNU compilers will not output anything for a successful compilation. Also, the Intel compiler does not recognize the suffix ".f95".
Here is some more documentation from other sources on OpenMP:
Intel MKL Library
Intel Math Kernel Library (MKL) contains ScaLAPACK, LAPACK, Sparse Solver, BLAS, Sparse BLAS, CBLAS, GMP, FFTs, DFTs, VSL, VML, and Interval Arithmetic routines. MKL resides in the directory stored in the environment variable MKL_HOME, after loading a version of the Intel compiler with module.
By using module load to load an Intel compiler your environment will have several variables set up to help link applications with MKL. Here are some example combinations of simplified linking options:
$ module load intel
$ echo $LINK_LAPACK
-L${MKL_HOME}/lib/intel64 -lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core -liomp5 -lpthread
$ echo $LINK_LAPACK95
-L${MKL_HOME}/lib/intel64 -lmkl_lapack95_lp64 -lmkl_blas95_lp64 -lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core -liomp5 -lpthread
RCAC recommends you use the provided variables to define MKL linking options in your compiling procedures. The Intel compiler modules also provide two other environment variables, LINK_LAPACK_STATIC and LINK_LAPACK95_STATIC that you may use if you need to link MKL statically.
RCAC recommends that you use dynamic linking of libguide. If so, define LD_LIBRARY_PATH such that you are using the correct version of libguide at run time. If you use static linking of libguide, then:
- If you use the Intel compilers, link in the libguide version that comes with the compiler (use the -openmp option).
- If you do not use the Intel compilers, link in the libguide version that comes with the Intel MKL above.
Here are some more documentation from other sources on the Intel MKL:
Provided Compilers
Compilers are available on Hammer for Fortran, C, and C++. Compiler sets from Intel and GNU are installed.
Detailed documentation on each compiler set available on Hammer follows.
On Hammer, the following set of compiler and libraries for building code are recommended:
- Intel 17.0.1.132
- MKL
To load the recommended set:
$ module load rcac
$ module list
More information about using these compilers:
GNU Compilers
The official name of the GNU compilers is "GNU Compiler Collection" or "GCC". To discover which versions are available:
$ module avail gccChoose an appropriate GCC module and load it. For example:
$ module load gccAn older version of the GNU compiler will be in your path by default. Do NOT use this version. Instead, load a newer version using the command module load gcc.
| Language | Serial Program | OpenMP Program |
|---|---|---|
| Fortran77 |
|
|
| Fortran90 |
|
|
| Fortran95 |
|
|
| C |
|
|
| C++ |
|
|
More information on compiler options appear in the official man pages, which are accessible with the man command after loading the appropriate compiler module.
For more documentation on the GCC compilers:
Intel Compilers
One or more versions of the Intel compiler are available on Hammer. To discover which ones:
$ module avail intelChoose an appropriate Intel module and load it. For example:
$ module load intel| Language | Serial Program | OpenMP Program |
|---|---|---|
| Fortran77 |
|
|
| Fortran90 |
|
|
| Fortran95 | (same as Fortran 90) | (same as Fortran 90) |
| C |
|
|
| C++ |
|
|
More information on compiler options appear in the official man pages, which are accessible with the man command after loading the appropriate compiler module.
For more documentation on the Intel compilers:
Compiling MPI Programs
OpenMPI and Intel MPI (IMPI) are implementations of the Message-Passing Interface (MPI) standard. Libraries for these MPI implementations and compilers for C, C++, and Fortran are available on all clusters.
| Language | Header Files |
|---|---|
| Fortran 77 |
|
| Fortran 90 |
|
| Fortran 95 |
|
| C |
|
| C++ |
|
Here are a few sample programs using MPI:
To see the available MPI libraries:
$ module avail openmpi
$ module avail impi
| Language | Intel MPI | OpenMPI |
|---|---|---|
| Fortran 77 |
|
|
| Fortran 90 |
|
|
| Fortran 95 |
|
|
| C |
|
|
| C++ |
|
|
The Intel and GNU compilers will not output anything for a successful compilation. Also, the Intel compiler does not recognize the suffix ".f95".
Here is some more documentation from other sources on the MPI libraries:
Running Jobs
There is one method for submitting jobs to Hammer. You may use SLURM to submit jobs to a partition on Hammer. SLURM performs job scheduling. Jobs may be any type of program. You may use either the batch or interactive mode to run your jobs. Use the batch mode for finished programs; use the interactive mode only for debugging.
In this section, you'll find a few pages describing the basics of creating and submitting SLURM jobs. As well, a number of example SLURM jobs that you may be able to adapt to your own needs.
PBS to Slurm
This is a reference for the most common command, environment variables, and job specification options used by the workload management systems and their equivalents.
Quick Guide
This table lists the most common command, environment variables, and job specification options used by the workload management systems and their equivalents (adapted from http://www.schedmd.com/slurmdocs/rosetta.html).
| User Commands | PBS/Torque | Slurm |
|---|---|---|
| Job submission | qsub [script_file] |
sbatch [script_file] |
| Interactive Job | qsub -I |
sinteractive |
| Job deletion | qdel [job_id] |
scancel [job_id] |
| Job status (by job) | qstat [job_id] |
squeue [-j job_id] |
| Job status (by user) | qstat -u [user_name] |
squeue [-u user_name] |
| Job hold | qhold [job_id] |
scontrol hold [job_id] |
| Job release | qrls [job_id] |
scontrol release [job_id] |
| Queue info | qstat -Q |
squeue |
| Queue access | qlist |
slist |
| Node list | pbsnodes -l |
sinfo -Nscontrol show nodes |
| Cluster status | qstat -a |
sinfo |
| GUI | xpbsmon |
sview |
| Environment | PBS/Torque | Slurm |
| Job ID | $PBS_JOBID |
$SLURM_JOB_ID |
| Job Name | $PBS_JOBNAME |
$SLURM_JOB_NAME |
| Job Queue/Account | $PBS_QUEUE |
$SLURM_JOB_ACCOUNT |
| Submit Directory | $PBS_O_WORKDIR |
$SLURM_SUBMIT_DIR |
| Submit Host | $PBS_O_HOST |
$SLURM_SUBMIT_HOST |
| Number of nodes | $PBS_NUM_NODES |
$SLURM_JOB_NUM_NODES |
| Number of Tasks | $PBS_NP |
$SLURM_NTASKS |
| Number of Tasks Per Node | $PBS_NUM_PPN |
$SLURM_NTASKS_PER_NODE |
| Node List (Compact) | n/a | $SLURM_JOB_NODELIST |
| Node List (One Core Per Line) | LIST=$(cat $PBS_NODEFILE) |
LIST=$(srun hostname) |
| Job Array Index | $PBS_ARRAYID |
$SLURM_ARRAY_TASK_ID |
| Job Specification | PBS/Torque | Slurm |
| Script directive | #PBS |
#SBATCH |
| Queue | -q [queue] |
-A [queue] |
| Node Count | -l nodes=[count] |
-N [min[-max]] |
| CPU Count | -l ppn=[count] |
-n [count]Note: total, not per node |
| Wall Clock Limit | -l walltime=[hh:mm:ss] |
-t [min] OR-t [hh:mm:ss] OR-t [days-hh:mm:ss] |
| Standard Output FIle | -o [file_name] |
-o [file_name] |
| Standard Error File | -e [file_name] |
-e [file_name] |
| Combine stdout/err | -j oe (both to stdout) OR-j eo (both to stderr) |
(use -o without -e) |
| Copy Environment | -V |
--export=[ALL | NONE | variables]Note: default behavior is ALL |
| Copy Specific Environment Variable | -v myvar=somevalue |
--export=NONE,myvar=somevalue OR--export=ALL,myvar=somevalue |
| Event Notification | -m abe |
--mail-type=[events] |
| Email Address | -M [address] |
--mail-user=[address] |
| Job Name | -N [name] |
--job-name=[name] |
| Job Restart | -r [y|n] |
--requeue OR--no-requeue |
| Working Directory | --workdir=[dir_name] |
|
| Resource Sharing | -l naccesspolicy=singlejob |
--exclusive OR--shared |
| Memory Size | -l mem=[MB] |
--mem=[mem][M|G|T] OR--mem-per-cpu=[mem][M|G|T] |
| Account to charge | -A [account] |
-A [account] |
| Tasks Per Node | -l ppn=[count] |
--tasks-per-node=[count] |
| CPUs Per Task | --cpus-per-task=[count] |
|
| Job Dependency | -W depend=[state:job_id] |
--depend=[state:job_id] |
| Job Arrays | -t [array_spec] |
--array=[array_spec] |
| Generic Resources | -l other=[resource_spec] |
--gres=[resource_spec] |
| Licenses | --licenses=[license_spec] |
|
| Begin Time | -A "y-m-d h:m:s" |
--begin=y-m-d[Th:m[:s]] |
See the official Slurm Documentation for further details.
Notable Differences
-
Separate commands for Batch and Interactive jobs
Unlike PBS, in Slurm interactive jobs and batch jobs are launched with completely distinct commands.
Usesbatch [allocation request options] scriptto submit a job to the batch scheduler, andsinteractive [allocation request options]to launch an interactive job. sinteractive accepts most of the same allocation request options as sbatch does. -
No need for
cd $PBS_O_WORKDIRIn Slurm your batch job starts to run in the directory from which you submitted the script whereas in PBS/Torque you need to explicitly move back to that directory with
cd $PBS_O_WORKDIR. -
No need to manually export environment
The environment variables that are defined in your shell session at the time that you submit the script are exported into your batch job, whereas in PBS/Torque you need to use the
-Vflag to export your environment. -
Location of output files
The output and error files are created in their final location immediately that the job begins or an error is generated, whereas in PBS/Torque temporary files are created that are only moved to the final location at the end of the job. Therefore in Slurm you can examine the output and error files from your job during its execution.
See the official Slurm Documentation for further details.
Basics of SLURM Jobs
The Simple Linux Utility for Resource Management (SLURM) is a system providing job scheduling and job management on compute clusters. With SLURM, a user requests resources and submits a job to a queue. The system will then take jobs from queues, allocate the necessary nodes, and execute them.
Do NOT run large, long, multi-threaded, parallel, or CPU-intensive jobs on a front-end login host. All users share the front-end hosts, and running anything but the smallest test job will negatively impact everyone's ability to use Hammer. Always use SLURM to submit your work as a job.
Link to section 'Submitting a Job' of 'Basics of SLURM Jobs' Submitting a Job
The main steps to submitting a job are:
Follow the links below for information on these steps, and other basic information about jobs. A number of example SLURM jobs are also available.
Job Submission Script
To submit work to a SLURM queue, you must first create a job submission file. This job submission file is essentially a simple shell script. It will set any required environment variables, load any necessary modules, create or modify files and directories, and run any applications that you need:
#!/bin/bash
# FILENAME: myjobsubmissionfile
# Loads Matlab and sets the application up
module load matlab
# Change to the directory from which you originally submitted this job.
cd $SLURM_SUBMIT_DIR
# Runs a Matlab script named 'myscript'
matlab -nodisplay -singleCompThread -r myscript
Once your script is prepared, you are ready to submit your job.
Link to section 'Job Script Environment Variables' of 'Job Submission Script' Job Script Environment Variables
| Name | Description |
|---|---|
| SLURM_SUBMIT_DIR | Absolute path of the current working directory when you submitted this job |
| SLURM_JOBID | Job ID number assigned to this job by the batch system |
| SLURM_JOB_NAME | Job name supplied by the user |
| SLURM_JOB_NODELIST | Names of nodes assigned to this job |
| SLURM_CLUSTER_NAME | Name of the cluster executing the job |
| SLURM_SUBMIT_HOST | Hostname of the system where you submitted this job |
| SLURM_JOB_PARTITION | Name of the original queue to which you submitted this job |
Submitting a Job
Once you have a job submission file, you may submit this script to SLURM using the sbatch command. SLURM will find, or wait for, available resources matching your request and run your job there.
To submit your job to one compute node:
$ sbatch --nodes=1 myjobsubmissionfile Slurm uses the word 'Account' and the option '-A' to specify different batch queues. To submit your job to a specific queue:
$ sbatch --nodes=1 -A standby myjobsubmissionfile By default, each job receives 30 minutes of wall time, or clock time. If you know that your job will not need more than a certain amount of time to run, request less than the maximum wall time, as this may allow your job to run sooner. To request the 1 hour and 30 minutes of wall time:
$ sbatch -t 1:30:00 --nodes=1 -A standby myjobsubmissionfile The --nodes value indicates how many compute nodes you would like for your job.
Each compute node in Hammer has 20 processor cores.
In some cases, you may want to request multiple nodes. To utilize multiple nodes, you will need to have a program or code that is specifically programmed to use multiple nodes such as with MPI. Simply requesting more nodes will not make your work go faster. Your code must support this ability.
To request 2 compute nodes:
$ sbatch --nodes=2 myjobsubmissionfile SLURM jobs will have exclusive access to compute nodes and other jobs will not use the same nodes. SLURM will allow a single job to run multiple tasks, and those tasks can be allocated resources with the --ntasks option.
To submit a job using 1 compute node with 4 tasks, each using the default 1 core and 1 GPU per node:
$ sbatch --nodes=1 --ntasks=4 --gpus-per-node=1 myjobsubmissionfileIf more convenient, you may also specify any command line options to sbatch from within your job submission file, using a special form of comment:
#!/bin/sh -l
# FILENAME: myjobsubmissionfile
#SBATCH -A myqueuename
#SBATCH --nodes=1
#SBATCH --time=1:30:00
#SBATCH --job-name myjobname
# Print the hostname of the compute node on which this job is running.
/bin/hostnameIf an option is present in both your job submission file and on the command line, the option on the command line will take precedence.
After you submit your job with SBATCH, it may wait in queue for minutes, hours, or even weeks. How long it takes for a job to start depends on the specific queue, the resources and time requested, and other jobs already waiting in that queue requested as well. It is impossible to say for sure when any given job will start. For best results, request no more resources than your job requires.
Once your job is submitted, you can monitor the job status, wait for the job to complete, and check the job output.
Checking Job Status
Once a job is submitted there are several commands you can use to monitor the progress of the job.
To see your jobs, use the squeue -u command and specify your username:
(Remember, in our SLURM environment a queue is referred to as an 'Account')
squeue -u myusername
JOBID ACCOUNT NAME USER ST TIME NODES NODELIST(REASON)
182792 standby job1 myusername R 20:19 1 hammer-a000
185841 standby job2 myusername R 20:19 1 hammer-a001
185844 standby job3 myusername R 20:18 1 hammer-a002
185847 standby job4 myusername R 20:18 1 hammer-a003
To retrieve useful information about your queued or running job, use the scontrol show job command with your job's ID number. The output should look similar to the following:
scontrol show job 3519
JobId=3519 JobName=t.sub
UserId=myusername GroupId=mygroup MCS_label=N/A
Priority=3 Nice=0 Account=(null) QOS=(null)
JobState=PENDING Reason=BeginTime Dependency=(null)
Requeue=1 Restarts=0 BatchFlag=1 Reboot=0 ExitCode=0:0
RunTime=00:00:00 TimeLimit=7-00:00:00 TimeMin=N/A
SubmitTime=2019-08-29T16:56:52 EligibleTime=2019-08-29T23:30:00
AccrueTime=Unknown
StartTime=2019-08-29T23:30:00 EndTime=2019-09-05T23:30:00 Deadline=N/A
PreemptTime=None SuspendTime=None SecsPreSuspend=0
LastSchedEval=2019-08-29T16:56:52
Partition=workq AllocNode:Sid=mack-fe00:54476
ReqNodeList=(null) ExcNodeList=(null)
NodeList=(null)
NumNodes=1 NumCPUs=2 NumTasks=2 CPUs/Task=1 ReqB:S:C:T=0:0:*:*
TRES=cpu=2,node=1,billing=2
Socks/Node=* NtasksPerN:B:S:C=0:0:*:* CoreSpec=*
MinCPUsNode=1 MinMemoryNode=0 MinTmpDiskNode=0
Features=(null) DelayBoot=00:00:00
OverSubscribe=OK Contiguous=0 Licenses=(null) Network=(null)
Command=/home/myusername/jobdir/myjobfile.sub
WorkDir=/home/myusername/jobdir
StdErr=/home/myusername/jobdir/slurm-3519.out
StdIn=/dev/null
StdOut=/home/myusername/jobdir/slurm-3519.out
Power=
There are several useful bits of information in this output.
JobStatelets you know if the job is Pending, Running, Completed, or Held.RunTime and TimeLimitwill show how long the job has run and its maximum time.SubmitTimeis when the job was submitted to the cluster.- The job's number of Nodes, Tasks, Cores (CPUs) and CPUs per Task are shown.
WorkDiris the job's working directory.StdOutandStderrare the locations of stdout and stderr of the job, respectively.Reasonwill show why aPENDINGjob isn't running. The above error says that it has been requested to start at a specific, later time.
Checking Job Output
Once a job is submitted, and has started, it will write its standard output and standard error to files that you can read.
SLURM catches output written to standard output and standard error - what would be printed to your screen if you ran your program interactively. Unless you specfied otherwise, SLURM will put the output in the directory where you submitted the job in a file named slurm- followed by the job id, with the extension out. For example slurm-3509.out. Note that both stdout and stderr will be written into the same file, unless you specify otherwise.
If your program writes its own output files, those files will be created as defined by the program. This may be in the directory where the program was run, or may be defined in a configuration or input file. You will need to check the documentation for your program for more details.
Link to section 'Redirecting Job Output' of 'Checking Job Output' Redirecting Job Output
It is possible to redirect job output to somewhere other than the default location with the --error and --output directives:
#!/bin/bash
#SBATCH --output=/home/myusername/joboutput/myjob.out
#SBATCH --error=/home/myusername/joboutput/myjob.out
# This job prints "Hello World" to output and exits
echo "Hello World"
Holding a Job
Sometimes you may want to submit a job but not have it run just yet. You may be wanting to allow lab mates to cut in front of you in the queue - so hold the job until their jobs have started, and then release yours.
To place a hold on a job before it starts running, use the scontrol hold job command:
$ scontrol hold job myjobidOnce a job has started running it can not be placed on hold.
To release a hold on a job, use the scontrol release job command:
$ scontrol release job myjobidYou find the job ID using the squeue command as explained in the SLURM Job Status section.
Job Dependencies
Dependencies are an automated way of holding and releasing jobs. Jobs with a dependency are held until the condition is satisfied. Once the condition is satisfied jobs only then become eligible to run and must still queue as normal.
Job dependencies may be configured to ensure jobs start in a specified order. Jobs can be configured to run after other job state changes, such as when the job starts or the job ends.
These examples illustrate setting dependencies in several ways. Typically dependencies are set by capturing and using the job ID from the last job submitted.
To run a job after job myjobid has started:
sbatch --dependency=after:myjobid myjobsubmissionfileTo run a job after job myjobid ends without error:
sbatch --dependency=afterok:myjobid myjobsubmissionfileTo run a job after job myjobid ends with errors:
sbatch --dependency=afternotok:myjobid myjobsubmissionfileTo run a job after job myjobid ends with or without errors:
sbatch --dependency=afterany:myjobid myjobsubmissionfileTo set more complex dependencies on multiple jobs and conditions:
sbatch --dependency=after:myjobid1:myjobid2:myjobid3,afterok:myjobid4 myjobsubmissionfileCanceling a Job
To stop a job before it finishes or remove it from a queue, use the scancel command:
scancel myjobidYou find the job ID using the squeue command as explained in the SLURM Job Status section.
Queues
Link to section '"mylab" Queues' of 'Queues' "mylab" Queues
Hammer, as a community cluster, has one or more queues dedicated to and named after each partner who has purchased access to the cluster. These queues provide partners and their researchers with priority access to their portion of the cluster. Jobs in these queues are typically limited to 336 hours. The expectation is that any jobs submitted to your research lab queues will start within 4 hours, assuming the queue currently has enough capacity for the job (that is, your lab mates aren't using all of the cores currently).
Link to section 'Standby Queue' of 'Queues' Standby Queue
Additionally, community clusters provide a "standby" queue which is available to all cluster users. This "standby" queue allows users to utilize portions of the cluster that would otherwise be idle, but at a lower priority than partner-queue jobs, and with a relatively short time limit, to ensure "standby" jobs will not be able to tie up resources and prevent partner-queue jobs from running quickly. Jobs in standby are limited to 4 hours. There is no expectation of job start time. If the cluster is very busy with partner queue jobs, or you are requesting a very large job, jobs in standby may take hours or days to start.
Link to section 'Debug Queue' of 'Queues' Debug Queue
The debug queue allows you to quickly start small, short, interactive jobs in order to debug code, test programs, or test configurations. You are limited to one running job at a time in the queue, and you may run up to two compute nodes for 30 minutes. The expectation is that debug jobs should start within a couple of minutes, assuming all of its dedicated nodes are not taken by others.
Link to section 'List of Queues' of 'Queues' List of Queues
To see a list of all queues on Hammer that you may submit to, use the slist command
This lists each queue you can submit to, the number of nodes allocated to the queue, how many are available to run jobs, and the maximum walltime you may request. Options to the command will give more detailed information. This command can be used to get a general idea of how busy an individual queue is and how long you may have to wait for your job to start.
Example Jobs
A number of example jobs are available for you to look over and adapt to your own needs. The first few are generic examples, and latter ones go into specifics for particular software packages.
Generic SLURM Jobs
The following examples demonstrate the basics of SLURM jobs, and are designed to cover common job request scenarios. These example jobs will need to be modified to run your application or code.
Simple Job
Every SLURM job consists of a job submission file. A job submission file contains a list of commands that run your program and a set of resource (nodes, walltime, queue) requests. The resource requests can appear in the job submission file or can be specified at submit-time as shown below.
This simple example submits the job submission file hello.sub to the standby queue on Hammer and requests a single node:
#!/bin/bash
# FILENAME: hello.sub
# Show this ran on a compute node by running the hostname command.
hostname
echo "Hello World"
sbatch -A standby --nodes=1 --ntasks=1 --cpus-per-task=1 --time=00:01:00 hello.sub
Submitted batch job 3521For a real job you would replace echo "Hello World" with a command, or sequence of commands, that run your program.
After your job finishes running, the ls command will show a new file in your directory, the .out file:
ls -l
hello.sub
slurm-3521.outThe file slurm-3521.out contains the output and errors your program would have written to the screen if you had typed its commands at a command prompt:
cat slurm-3521.out
hammer-a001.rcac.purdue.edu
Hello WorldYou should see the hostname of the compute node your job was executed on. Following should be the "Hello World" statement.
Multiple Node
In some cases, you may want to request multiple nodes. To utilize multiple nodes, you will need to have a program or code that is specifically programmed to use multiple nodes such as with MPI. Simply requesting more nodes will not make your work go faster. Your code must support this ability.
This example shows a request for multiple compute nodes. The job submission file contains a single command to show the names of the compute nodes allocated:
# FILENAME: myjobsubmissionfile.sub
echo "$SLURM_JOB_NODELIST"
sbatch --nodes=2 --ntasks=40 --time=00:10:00 -A standby myjobsubmissionfile.subCompute nodes allocated:
hammer-a[014-015]
The above example will allocate the total of 40 CPU cores across 2 nodes. Note that if your multi-node job requests fewer than each node's full 20 cores per node, by default Slurm provides no guarantee with respect to how this total is distributed between assigned nodes (i.e. the cores may not necessarily be split evenly). If you need specific arrangements of your tasks and cores, you can use --cpus-per-task= and/or --ntasks-per-node= flags. See Slurm documentation or man sbatch for more options.
Directives
So far these examples have shown submitting jobs with the resource requests on the sbatch command line such as:
sbatch -A standby --nodes=1 --time=00:01:00 hello.subThe resource requests can also be put into job submission file itself. Documenting the resource requests in the job submission is desirable because the job can be easily reproduced later. Details left in your command history are quickly lost. Arguments are specified with the #SBATCH syntax:
#!/bin/bash
# FILENAME: hello.sub
#SBATCH -A standby
#SBATCH --nodes=1 --time=00:01:00
# Show this ran on a compute node by running the hostname command.
hostname
echo "Hello World"
The #SBATCH directives must appear at the top of your submission file. SLURM will stop parsing directives as soon as it encounters a line that does not start with '#'. If you insert a directive in the middle of your script, it will be ignored.
This job can be then submitted with:
sbatch hello.subSpecific Types of Nodes
SLURM allows running a job on specific types of compute nodes to accommodate special hardware requirements (e.g. a certain CPU or GPU type, etc.)
Cluster nodes have a set of descriptive features assigned to them, and users can specify which of these features are required by their job by using the constraint option at submission time. Only nodes having features matching the job constraints will be used to satisfy the request.
Example: a job requires a compute node in an "A" sub-cluster:
sbatch --nodes=1 --ntasks=20 --constraint=A myjobsubmissionfile.subCompute node allocated:
hammer-a003Feature constraints can be used for both batch and interactive jobs, as well as for individual job steps inside a job. Multiple constraints can be specified with a predefined syntax to achieve complex request logic (see detailed description of the '--constraint' option in man sbatch or online Slurm documentation).
Refer to Detailed Hardware Specification section for list of available sub-cluster labels, their respective per-node memory sizes and other hardware details. You could also use sfeatures command to list available constraint feature names for different node types.
Interactive Jobs
Interactive jobs are run on compute nodes, while giving you a shell to interact with. They give you the ability to type commands or use a graphical interface in the same way as if you were on a front-end login host.
To submit an interactive job, use sinteractive to run a login shell on allocated resources.
sinteractive accepts most of the same resource requests as sbatch, so to request a login shell on the standby account while allocating 2 nodes and 20 total cores, you might do:
sinteractive -A standby -N2 -n40To quit your interactive job:
exit or Ctrl-D
The above example will allocate the total of 40 CPU cores across 2 nodes. Note that if your multi-node job requests fewer than each node's full 20 cores per node, by default Slurm provides no guarantee with respect to how this total is distributed between assigned nodes (i.e. the cores may not necessarily be split evenly). If you need specific arrangements of your tasks and cores, you can use --cpus-per-task= and/or --ntasks-per-node= flags. See Slurm documentation or man salloc for more options.
Serial Jobs
This shows how to submit one of the serial programs compiled in the section Compiling Serial Programs.
Create a job submission file:
#!/bin/bash
# FILENAME: serial_hello.sub
./serial_hello
Submit the job:
sbatch --nodes=1 --ntasks=1 --time=00:01:00 serial_hello.subAfter the job completes, view results in the output file:
cat slurm-myjobid.out
Runhost:hammer-a009.rcac.purdue.edu
hello, world
If the job failed to run, then view error messages in the file slurm-myjobid.out.
OpenMP
A shared-memory job is a single process that takes advantage of a multi-core processor and its shared memory to achieve parallelization.
This example shows how to submit an OpenMP program compiled in the section Compiling OpenMP Programs.
When running OpenMP programs, all threads must be on the same compute node to take advantage of shared memory. The threads cannot communicate between nodes.
To run an OpenMP program, set the environment variable OMP_NUM_THREADS to the desired number of threads:
In csh:
setenv OMP_NUM_THREADS 20In bash:
export OMP_NUM_THREADS=20This should almost always be equal to the number of cores on a compute node. You may want to set to another appropriate value if you are running several processes in parallel in a single job or node.
Create a job submissionfile:
#!/bin/bash
# FILENAME: omp_hello.sub
#SBATCH --nodes=1
#SBATCH --ntasks=20
#SBATCH --time=00:01:00
export OMP_NUM_THREADS=20
./omp_hello
Submit the job:
sbatch omp_hello.subView the results from one of the sample OpenMP programs about task parallelism:
cat omp_hello.sub.omyjobid
SERIAL REGION: Runhost:hammer-a003.rcac.purdue.edu Thread:0 of 1 thread hello, world
PARALLEL REGION: Runhost:hammer-a003.rcac.purdue.edu Thread:0 of 20 threads hello, world
PARALLEL REGION: Runhost:hammer-a003.rcac.purdue.edu Thread:1 of 20 threads hello, world
...If the job failed to run, then view error messages in the file slurm-myjobid.out.
If an OpenMP program uses a lot of memory and 20 threads use all of the memory of the compute node, use fewer processor cores (OpenMP threads) on that compute node.
MPI
An MPI job is a set of processes that take advantage of multiple compute nodes by communicating with each other. OpenMPI and Intel MPI (IMPI) are implementations of the MPI standard.
This section shows how to submit one of the MPI programs compiled in the section Compiling MPI Programs.
Use module load to set up the paths to access these libraries. Use module avail to see all MPI packages installed on Hammer.
Create a job submission file:
#!/bin/bash
# FILENAME: mpi_hello.sub
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=20
#SBATCH --time=00:01:00
#SBATCH -A standby
srun -n 40 ./mpi_hello
SLURM can run an MPI program with the srun command. The number of processes is requested with the -n option. If you do not specify the -n option, it will default to the total number of processor cores you request from SLURM.
If the code is built with OpenMPI, it can be run with a simple srun -n command. If it is built with Intel IMPI, then you also need to add the --mpi=pmi2 option: srun --mpi=pmi2 -n 40 ./mpi_hello in this example.
Submit the MPI job:
sbatch ./mpi_hello.subView results in the output file:
cat slurm-myjobid.out
Runhost:hammer-a010.rcac.purdue.edu Rank:0 of 40 ranks hello, world
Runhost:hammer-a010.rcac.purdue.edu Rank:1 of 40 ranks hello, world
...
Runhost:hammer-a011.rcac.purdue.edu Rank:20 of 40 ranks hello, world
Runhost:hammer-a011.rcac.purdue.edu Rank:21 of 40 ranks hello, world
...If the job failed to run, then view error messages in the output file.
If an MPI job uses a lot of memory and 20 MPI ranks per compute node use all of the memory of the compute nodes, request more compute nodes, while keeping the total number of MPI ranks unchanged.
Submit the job with double the number of compute nodes and modify the resource request to halve the number of MPI ranks per compute node.
#!/bin/bash
# FILENAME: mpi_hello.sub
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=10
#SBATCH -t 00:01:00
#SBATCH -A standby
srun -n 40 ./mpi_hello
sbatch ./mpi_hello.subView results in the output file:
cat slurm-myjobid.out
Runhost:hammer-a10.rcac.purdue.edu Rank:0 of 40 ranks hello, world
Runhost:hammer-a010.rcac.purdue.edu Rank:1 of 40 ranks hello, world
...
Runhost:hammer-a011.rcac.purdue.edu Rank:10 of 40 ranks hello, world
...
Runhost:hammer-a012.rcac.purdue.edu Rank:20 of 40 ranks hello, world
...
Runhost:hammer-a013.rcac.purdue.edu Rank:30 of 40 ranks hello, world
...Notes
- Use slist to determine which queues (
--accountor-Aoption) are available to you. The name of the queue which is available to everyone on Hammer is "standby". - Invoking an MPI program on Hammer with ./program is typically wrong, since this will use only one MPI process and defeat the purpose of using MPI. Unless that is what you want (rarely the case), you should use srun or mpiexec to invoke an MPI program.
- In general, the exact order in which MPI ranks output similar write requests to an output file is random.
Link to section 'Collecting System Resource Utilization Data' of 'Monitoring Resources' Collecting System Resource Utilization Data
Knowing the precise resource utilization an application had during a job, such as CPU load or memory, can be incredibly useful. This is especially the case when the application isn't performing as expected.
One approach is to run a program like htop during an interactive job and keep an eye on system resources. You can get precise time-series data from nodes associated with your job using XDmod as well, online. But these methods don't gather telemetry in an automated fashion, nor do they give you control over the resolution or format of the data.
As a matter of course, a robust implementation of some HPC workload would include resource utilization data as a diagnostic tool in the event of some failure.
The monitor utility is a simple command line system resource monitoring tool for gathering such telemetry and is available as a module.
module load utilities monitor
Complete documentation is available online at resource-monitor.readthedocs.io. A full manual page is also available for reference, man monitor.
In the context of a SLURM job you will need to put this monitoring task in the background to allow the rest of your job script to proceed. Be sure to interrupt these tasks at the end of your job.
#!/bin/bash
# FILENAME: monitored_job.sh
module load utilities monitor
# track per-code CPU load
monitor cpu percent --all-cores >cpu-percent.log &
CPU_PID=$!
# track memory usage
monitor cpu memory >cpu-memory.log &
MEM_PID=$!
# your code here
# shut down the resource monitors
kill -s INT $CPU_PID $MEM_PID
A particularly elegant solution would be to include such tools in your prologue script and have the tear down in your epilogue script.
For large distributed jobs spread across multiple nodes, mpiexec can be used to gather telemetry from all nodes in the job. The hostname is included in each line of output so that data can be grouped as such. A concise way of constructing the needed list of hostnames in SLURM is to simply use srun hostname | sort -u.
#!/bin/bash
# FILENAME: monitored_job.sh
module load utilities monitor
# track all CPUs (one monitor per host)
mpiexec -machinefile <(srun hostname | sort -u) \
monitor cpu percent --all-cores >cpu-percent.log &
CPU_PID=$!
# track memory on all hosts (one monitor per host)
mpiexec -machinefile <(srun hostname | sort -u) \
monitor cpu memory >cpu-memory.log &
MEM_PID=$!
# your code here
# shut down the resource monitors
kill -s INT $CPU_PID $MEM_PID
To get resource data in a more readily computable format, the monitor program can be told to output in CSV format with the --csv flag.
monitor cpu memory --csv >cpu-memory.csv
For a distributed job you will need to suppress the header lines otherwise one will be created by each host.
monitor cpu memory --csv | head -1 >cpu-memory.csv
mpiexec -machinefile <(srun hostname | sort -u) \
monitor cpu memory --csv --no-header >>cpu-memory.csv
Specific Applications
The following examples demonstrate job submission files for some common real-world applications. See the Generic SLURM Examples section for more examples on job submissions that can be adapted for use.
Gaussian
Gaussian is a computational chemistry software package which works on electronic structure. This section illustrates how to submit a small Gaussian job to a Slurm queue. This Gaussian example runs the Fletcher-Powell multivariable optimization.
Prepare a Gaussian input file with an appropriate filename, here named myjob.com. The final blank line is necessary:
#P TEST OPT=FP STO-3G OPTCYC=2
STO-3G FLETCHER-POWELL OPTIMIZATION OF WATER
0 1
O
H 1 R
H 1 R 2 A
R 0.96
A 104.
To submit this job, load Gaussian then run the provided script, named subg16. This job uses one compute node with 20 processor cores:
module load gaussian16
subg16 myjob -N 1 -n 20
View job status:
squeue -u myusername
View results in the file for Gaussian output, here named myjob.log. Only the first and last few lines appear here:
Entering Gaussian System, Link 0=/apps/cent7/gaussian/g16-A.03/g16-haswell/g16/g16
Initial command:
/apps/cent7/gaussian/g16-A.03/g16-haswell/g16/l1.exe ${resource.scratch}/m/myusername/gaussian/Gau-7781.inp -scrdir=${resource.scratch}/m/myusername/gaussian/
Entering Link 1 = /apps/cent7/gaussian/g16-A.03/g16-haswell/g16/l1.exe PID= 7782.
Copyright (c) 1988,1990,1992,1993,1995,1998,2003,2009,2016,
Gaussian, Inc. All Rights Reserved.
.
.
.
Job cpu time: 0 days 0 hours 3 minutes 28.2 seconds.
Elapsed time: 0 days 0 hours 0 minutes 12.9 seconds.
File lengths (MBytes): RWF= 17 Int= 0 D2E= 0 Chk= 2 Scr= 2
Normal termination of Gaussian 16 at Tue May 1 17:12:00 2018.
real 13.85
user 202.05
sys 6.12
Machine:
hammer-a012.rcac.purdue.edu
hammer-a012.rcac.purdue.edu
hammer-a012.rcac.purdue.edu
hammer-a012.rcac.purdue.edu
hammer-a012.rcac.purdue.edu
hammer-a012.rcac.purdue.edu
hammer-a012.rcac.purdue.edu
hammer-a012.rcac.purdue.edu
Link to section 'Examples of Gaussian SLURM Job Submissions' of 'Gaussian' Examples of Gaussian SLURM Job Submissions
Submit job using 20 processor cores on a single node:
subg16 myjob -N 1 -n 20 -t 200:00:00 -A myqueuename
Submit job using 20 processor cores on each of 2 nodes:
subg16 myjob -N 2 --ntasks-per-node=20 -t 200:00:00 -A myqueuename
To submit a bash job, a submit script sample looks like:
#!/bin/bash
#SBATCH -A myqueuename # Queue name(use 'slist' command to find queues' name)
#SBATCH --nodes=1 # Total # of nodes
#SBATCH --ntasks=64 # Total # of MPI tasks
#SBATCH --time=1:00:00 # Total run time limit (hh:mm:ss)
#SBATCH -J myjobname # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
module load gaussian16
g16 < myjob.com
For more information about Gaussian:
Machine Learning
We support several common machine learning (ML) frameworks on the community clusters through pre-installed modules. The collection of these pre-installed ML modules is referred to as ml-toolkit throughout this documentation. Currently, the following libraries are included in ML-Toolkit.
caffe cntk gym keras
mxnet opencv pytorch
tensorflow tflearn theano
Note that managing dependencies with ML applications can be non-trivial, therefore, we recommend users start by using ml-toolkit. If a custom installation is required after trying ml-toolkit, make sure to read documentation carefully.
ML-Toolkit
A set of pre-installed popular machine learning (ML) libraries, called ML-Toolkit is maintained on Hammer. These are Anaconda/Python-based distributions of the respective libraries. Currently, applications are supported for Python 2 and 3. Detailed instructions for searching and using the installed ML applications are presented below.
Link to section 'Instructions for using ML-Toolkit Modules' of 'ML-Toolkit' Instructions for using ML-Toolkit Modules
Link to section 'Find and Use Installed ML Packages' of 'ML-Toolkit' Find and Use Installed ML Packages
To search or load a machine learning application, you must first load one of the learning modules. The learning module loads the prerequisites (such as anaconda) and makes ML applications visible to the user.
Step 1. Find and load a preferred learning module. Several learning modules may be available, corresponding to a specific Python version and whether the ML applications have GPU support or not. Running module load learning without specifying a version will load the version with the most recent python version. To see all available modules, run module spider learning then load the desired module.
Step 2. Find and load the desired machine learning libraries
ML packages are installed under the common application name ml-toolkit-cpu
You can use the module spider ml-toolkit command to see all options and versions of each library.
Load the desired modules using the module load command. Note that both CPU and GPU options may exist for many libraries, so be sure to load the correct version. For example, if you wanted to load the most recent version of PyTorch for CPU, you would run module load ml-toolkit-cpu/pytorch
caffe cntk gym keras mxnet
opencv pytorch tensorflow tflearn theano
Step 3. You can list which ML applications are loaded in your environment using the command module list
Link to section 'Verify application import' of 'ML-Toolkit' Verify application import
Step 4. The next step is to check that you can actually use the desired ML application. You can do this by running the import command in Python. The example below tests if PyTorch has been loaded correctly.
python -c "import torch; print(torch.__version__)"
If the import operation succeeded, then you can run your own ML code. Some ML applications (such as tensorflow) print diagnostic warnings while loading -- this is the expected behavior.
If the import fails with an error, please see the troubleshooting information below.
Step 5. To load a different set of applications, unload the previously loaded applications and load the new desired applications. The example below loads Tensorflow and Keras instead of PyTorch and OpenCV.
module unload ml-toolkit-cpu/opencv
module unload ml-toolkit-cpu/pytorch
module load ml-toolkit-cpu/tensorflow
module load ml-toolkit-cpu/keras
Link to section 'Troubleshooting' of 'ML-Toolkit' Troubleshooting
ML applications depend on a wide range of Python packages and mixing multiple versions of these packages can lead to error. The following guidelines will assist you in identifying the cause of the problem.
- Check that you are using the correct version of Python with the command python --version. This should match the Python version in the loaded anaconda module.
- Start from a clean environment. Either start a new terminal session or unload all the modules using module purge. Then load the desired modules following Steps 1-2.
- Verify that PYTHONPATH does not point to undesired packages. Run the following command to print PYTHONPATH: echo $PYTHONPATH. Make sure that your Python environment is clean. Watch out for any locally installed packages that might conflict.
- Note that Caffe has a conflicting version of PyQt5. So, if you want to use Spyder (or any GUI application that uses PyQt), then you should unload the caffe module.
- Use Google search to your advantage. Copy the error message in Google and check probable causes.
More examples showing how to use ml-toolkit modules in a batch job are presented in ML Batch Jobs guide.
Link to section 'Running ML Code in a Batch Job' of 'ML Batch Jobs' Running ML Code in a Batch Job
Batch jobs allow us to automate model training without human intervention. They are also useful when you need to run a large number of simulations on the clusters. In the example below, we shall run a simple tensor_hello.py script in a batch job. We consider two situations: in the first example, we use the ML-Toolkit modules to run tensorflow, while in the second example, we use a custom installation of tensorflow (See Custom ML Packages page).
Link to section 'Using ML-Toolkit Modules' of 'ML Batch Jobs' Using ML-Toolkit Modules
Save the following code as tensor_hello.sub in the same directory where tensor_hello.py is located.
# filename: tensor_hello.sub
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=20
#SBATCH --time=00:05:00
#SBATCH -A standby
#SBATCH -J hello_tensor
module purge
module load learning
module load ml-toolkit-cpu/tensorflow
module list
python tensor_hello.py
Link to section 'Using a Custom Installation' of 'ML Batch Jobs' Using a Custom Installation
Save the following code as tensor_hello.sub in the same directory where tensor_hello.py is located.
# filename: tensor_hello.sub
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=20
#SBATCH --time=00:05:00
#SBATCH -A standby
#SBATCH -J hello_tensor
module purge
module load anaconda
module load use.own
module load conda-env/my_tf_env-py3.6.4
module list
echo $PYTHONPATH
python tensor_hello.py
Link to section 'Running a Job' of 'ML Batch Jobs' Running a Job
Now you can submit the batch job using the sbatch command.
sbatch tensor_hello.sub
Once the job finishes, you will find an output file (slurm-xxxxx.out).
Link to section 'Installation of Custom ML Libraries' of 'Custom ML Packages' Installation of Custom ML Libraries
While we try to include as many common ML frameworks and versions as we can in ML-Toolkit, we recognize that there are also situations in which a custom installation may be preferable. We recommend using conda-env-mod to install and manage Python packages. Please follow the steps carefully, otherwise you may end up with a faulty installation. The example below shows how to install TensorFlow in your home directory.
Link to section 'Install' of 'Custom ML Packages' Install
Step 1: Unload all modules and start with a clean environment.
module purge
Step 2: Load the anaconda module with desired Python version.
module load anaconda
Step 3: Create a custom anaconda environment. Make sure the python version matches the Python version in the anaconda module.
conda-env-mod create -n env_name_here
Step 4: Activate the anaconda environment by loading the modules displayed at the end of step 3.
module load use.own
module load conda-env/env_name_here-py3.6.4
Step 5: Now install the desired ML application. You can install multiple Python packages at this step using either conda or pip.
pip install --ignore-installed tensorflow==2.6
If the installation succeeded, you can now proceed to testing and using the installed application. You must load the environment you created as well as any supporting modules (e.g., anaconda) whenever you want to use this installation. If your installation did not succeed, please refer to the troubleshooting section below as well as documentation for the desired package you are installing.
Note that loading the modules generated by conda-env-mod has different behavior than conda create env_name_here followed by source activate env_name_here. After running source activate, you may not be able to access any Python packages in anaconda or ml-toolkit modules. Therefore, using conda-env-mod is the preferred way of using your custom installations.
Link to section 'Testing the Installation' of 'Custom ML Packages' Testing the Installation
-
Verify the installation by using a simple import statement, like that listed below for TensorFlow:
python -c "import tensorflow as tf; print(tf.__version__);"Note that a successful import of TensorFlow will print a variety of system and hardware information. This is expected.
If importing the package leads to errors, be sure to verify that all dependencies for the package have been managed, and the correct versions installed. Dependency issues between python packages are the most common cause for errors. For example, in TF, conflicts with the h5py or numpy versions are common, but upgrading those packages typically solves the problem. Managing dependencies for ML libraries can be non-trivial.
-
Link to section 'Troubleshooting' of 'Custom ML Packages' Troubleshooting
In most situations, dependencies among Python modules lead to errors. If you cannot use a Python package after installing it, please follow the steps below to find a workaround.
- Unload all the modules.
module purge - Clean up PYTHONPATH.
unset PYTHONPATH - Next load the modules, e.g., anaconda and your custom environment.
module load anaconda module load use.own module load conda-env/env_name_here-py3.6.4 - Now try running your code again.
- A few applications only run on specific versions of Python (e.g. Python 3.6). Please check the documentation of your application if that is the case.
- If you have installed a newer version of an ml-toolkit package (e.g., a newer version of PyTorch or Tensorflow), make sure that the ml-toolkit modules are NOT loaded. In general, we recommend that you don't mix ml-toolkit modules with your custom installations.
Link to section 'Tensorboard' of 'Custom ML Packages' Tensorboard
- You can visualize data from a Tensorflow session using Tensorboard. For this, you need to save your session summary as described in the Tensorboard User Guide.
- Launch Tensorboard:
$ python -m tensorboard.main --logdir=/path/to/session/logs - When Tensorboard is launched successfully, it will give you the URL for accessing Tensorboard.
<... build related warnings ...> TensorBoard 0.4.0 at http://hammer-a000.rcac.purdue.edu:6006 - Follow the printed URL to visualize your model.
- Please note that due to firewall rules, the Tensorboard URL may only be accessible from Hammer nodes. If you cannot access the URL directly, you can use Firefox browser in Thinlinc.
- For more details, please refer to the Tensorboard User Guide.
- Unload all the modules.
Matlab
MATLAB® (MATrix LABoratory) is a high-level language and interactive environment for numerical computation, visualization, and programming. MATLAB is a product of MathWorks.
MATLAB, Simulink, Compiler, and several of the optional toolboxes are available to faculty, staff, and students. To see the kind and quantity of all MATLAB licenses plus the number that you are currently using you can use the matlab_licenses command:
$ module load matlab
$ matlab_licenses
The MATLAB client can be run in the front-end for application development, however, computationally intensive jobs must be run on compute nodes.
The following sections provide several examples illustrating how to submit MATLAB jobs to a Linux compute cluster.
Matlab Script (.m File)
This section illustrates how to submit a small, serial, MATLAB program as a job to a batch queue. This MATLAB program prints the name of the run host and gets three random numbers.
Prepare a MATLAB script myscript.m, and a MATLAB function file myfunction.m:
% FILENAME: myscript.m
% Display name of compute node which ran this job.
[c name] = system('hostname');
fprintf('\n\nhostname:%s\n', name);
% Display three random numbers.
A = rand(1,3);
fprintf('%f %f %f\n', A);
quit;
% FILENAME: myfunction.m
function result = myfunction ()
% Return name of compute node which ran this job.
[c name] = system('hostname');
result = sprintf('hostname:%s', name);
% Return three random numbers.
A = rand(1,3);
r = sprintf('%f %f %f', A);
result=strvcat(result,r);
end
Also, prepare a job submission file, here named myjob.sub. Run with the name of the script:
#!/bin/bash
# FILENAME: myjob.sub
echo "myjob.sub"
# Load module, and set up environment for Matlab to run
module load matlab
unset DISPLAY
# -nodisplay: run MATLAB in text mode; X11 server not needed
# -singleCompThread: turn off implicit parallelism
# -r: read MATLAB program; use MATLAB JIT Accelerator
# Run Matlab, with the above options and specifying our .m file
matlab -nodisplay -singleCompThread -r myscript
myjob.sub
< M A T L A B (R) >
Copyright 1984-2011 The MathWorks, Inc.
R2011b (7.13.0.564) 64-bit (glnxa64)
August 13, 2011
To get started, type one of these: helpwin, helpdesk, or demo.
For product information, visit www.mathworks.com.
hostname:hammer-a001.rcac.purdue.edu
0.814724 0.905792 0.126987
Output shows that a processor core on one compute node (hammer-a001) processed the job. Output also displays the three random numbers.
For more information about MATLAB:
Implicit Parallelism
MATLAB implements implicit parallelism which is automatic multithreading of many computations, such as matrix multiplication, linear algebra, and performing the same operation on a set of numbers. This is different from the explicit parallelism of the Parallel Computing Toolbox.
MATLAB offers implicit parallelism in the form of thread-parallel enabled functions. Since these processor cores, or threads, share a common memory, many MATLAB functions contain multithreading potential. Vector operations, the particular application or algorithm, and the amount of computation (array size) contribute to the determination of whether a function runs serially or with multithreading.
When your job triggers implicit parallelism, it attempts to allocate its threads on all processor cores of the compute node on which the MATLAB client is running, including processor cores running other jobs. This competition can degrade the performance of all jobs running on the node.
When you know that you are coding a serial job but are unsure whether you are using thread-parallel enabled operations, run MATLAB with implicit parallelism turned off. Beginning with the R2009b, you can turn multithreading off by starting MATLAB with -singleCompThread:
$ matlab -nodisplay -singleCompThread -r mymatlabprogram
When you are using implicit parallelism, make sure you request exclusive access to a compute node, as MATLAB has no facility for sharing nodes.
For more information about MATLAB's implicit parallelism:
Profile Manager
MATLAB offers two kinds of profiles for parallel execution: the 'local' profile and user-defined cluster profiles. The 'local' profile runs a MATLAB job on the processor core(s) of the same compute node, or front-end, that is running the client. To run a MATLAB job on compute node(s) different from the node running the client, you must define a Cluster Profile using the Cluster Profile Manager.
To prepare a user-defined cluster profile, use the Cluster Profile Manager in the Parallel menu. This profile contains the scheduler details (queue, nodes, processors, walltime, etc.) of your job submission. Ultimately, your cluster profile will be an argument to MATLAB functions like batch().
For your convenience, a generic cluster profile is provided that can be downloaded: myslurmprofile.settings
Please note that modifications are very likely to be required to make myslurmprofile.settings work. You may need to change values for number of nodes, number of workers, walltime, and submission queue specified in the file. As well, the generic profile itself depends on the particular job scheduler on the cluster, so you may need to download or create two or more generic profiles under different names. Each time you run a job using a Cluster Profile, make sure the specific profile you are using is appropriate for the job and the cluster.
To import the profile, start a MATLAB session and select Manage Cluster Profiles... from the Parallel menu. In the Cluster Profile Manager, select Import, navigate to the folder containing the profile, select myslurmprofile.settings and click OK. Remember that the profile will need to be customized for your specific needs. If you have any questions, please contact us.
For detailed information about MATLAB's Parallel Computing Toolbox, examples, demos, and tutorials:
Parallel Computing Toolbox (parfor)
The MATLAB Parallel Computing Toolbox (PCT) extends the MATLAB language with high-level, parallel-processing features such as parallel for loops, parallel regions, message passing, distributed arrays, and parallel numerical methods. It offers a shared-memory computing environment running on the local cluster profile in addition to your MATLAB client. Moreover, the MATLAB Distributed Computing Server (DCS) scales PCT applications up to the limit of your DCS licenses.
This section illustrates the fine-grained parallelism of a parallel for loop (parfor) in a pool job.
The following examples illustrate a method for submitting a small, parallel, MATLAB program with a parallel loop (parfor statement) as a job to a queue. This MATLAB program prints the name of the run host and shows the values of variables numlabs and labindex for each iteration of the parfor loop.
This method uses the job submission command to submit a MATLAB client which calls the MATLAB batch() function with a user-defined cluster profile.
Prepare a MATLAB pool program in a MATLAB script with an appropriate filename, here named myscript.m:
% FILENAME: myscript.m
% SERIAL REGION
[c name] = system('hostname');
fprintf('SERIAL REGION: hostname:%s\n', name)
numlabs = parpool('poolsize');
fprintf(' hostname numlabs labindex iteration\n')
fprintf(' ------------------------------- ------- -------- ---------\n')
tic;
% PARALLEL LOOP
parfor i = 1:8
[c name] = system('hostname');
name = name(1:length(name)-1);
fprintf('PARALLEL LOOP: %-31s %7d %8d %9d\n', name,numlabs,labindex,i)
pause(2);
end
% SERIAL REGION
elapsed_time = toc; % get elapsed time in parallel loop
fprintf('\n')
[c name] = system('hostname');
name = name(1:length(name)-1);
fprintf('SERIAL REGION: hostname:%s\n', name)
fprintf('Elapsed time in parallel loop: %f\n', elapsed_time)
The execution of a pool job starts with a worker executing the statements of the first serial region up to the parfor block, when it pauses. A set of workers (the pool) executes the parfor block. When they finish, the first worker resumes by executing the second serial region. The code displays the names of the compute nodes running the batch session and the worker pool.
Prepare a MATLAB script that calls MATLAB function batch() which makes a four-lab pool on which to run the MATLAB code in the file myscript.m. Use an appropriate filename, here named mylclbatch.m:
% FILENAME: mylclbatch.m
!echo "mylclbatch.m"
!hostname
pjob=batch('myscript','Profile','myslurmprofile','Pool',4,'CaptureDiary',true);
wait(pjob);
diary(pjob);
quit;
Prepare a job submission file with an appropriate filename, here named myjob.sub:
#!/bin/bash
# FILENAME: myjob.sub
echo "myjob.sub"
hostname
module load matlab
unset DISPLAY
matlab -nodisplay -r mylclbatch
Submit the job as a single compute node with one processor core.
One processor core runs myjob.sub and mylclbatch.m.
Once this job starts, a second job submission is made.
myjob.sub
< M A T L A B (R) >
Copyright 1984-2013 The MathWorks, Inc.
R2013a (8.1.0.604) 64-bit (glnxa64)
February 15, 2013
To get started, type one of these: helpwin, helpdesk, or demo.
For product information, visit www.mathworks.com.
mylclbatch.mhammer-a000.rcac.purdue.edu
SERIAL REGION: hostname:hammer-a000.rcac.purdue.edu
hostname numlabs labindex iteration
------------------------------- ------- -------- ---------
PARALLEL LOOP: hammer-a001.rcac.purdue.edu 4 1 2
PARALLEL LOOP: hammer-a002.rcac.purdue.edu 4 1 4
PARALLEL LOOP: hammer-a001.rcac.purdue.edu 4 1 5
PARALLEL LOOP: hammer-a002.rcac.purdue.edu 4 1 6
PARALLEL LOOP: hammer-a003.rcac.purdue.edu 4 1 1
PARALLEL LOOP: hammer-a003.rcac.purdue.edu 4 1 3
PARALLEL LOOP: hammer-a004.rcac.purdue.edu 4 1 7
PARALLEL LOOP: hammer-a004.rcac.purdue.edu 4 1 8
SERIAL REGION: hostname:hammer-a001.rcac.purdue.edu
Elapsed time in parallel loop: 5.411486
To scale up this method to handle a real application, increase the wall time in the submission command to accommodate a longer running job. Secondly, increase the wall time of myslurmprofile by using the Cluster Profile Manager in the Parallel menu to enter a new wall time in the property SubmitArguments.
For more information about MATLAB Parallel Computing Toolbox:
Parallel Toolbox (spmd)
The MATLAB Parallel Computing Toolbox (PCT) extends the MATLAB language with high-level, parallel-processing features such as parallel for loops, parallel regions, message passing, distributed arrays, and parallel numerical methods. It offers a shared-memory computing environment with a maximum of eight MATLAB workers (labs, threads; versions R2009a) and 12 workers (labs, threads; version R2011a) running on the local configuration in addition to your MATLAB client. Moreover, the MATLAB Distributed Computing Server (DCS) scales PCT applications up to the limit of your DCS licenses.
This section illustrates how to submit a small, parallel, MATLAB program with a parallel region (spmd statement) as a MATLAB pool job to a batch queue.
This example uses the submission command to submit to compute nodes a MATLAB client which interprets a Matlab .m with a user-defined cluster profile which scatters the MATLAB workers onto different compute nodes. This method uses the MATLAB interpreter, the Parallel Computing Toolbox, and the Distributed Computing Server; so, it requires and checks out six licenses: one MATLAB license for the client running on the compute node, one PCT license, and four DCS licenses. Four DCS licenses run the four copies of the spmd statement. This job is completely off the front end.
Prepare a MATLAB script called myscript.m:
% FILENAME: myscript.m
% SERIAL REGION
[c name] = system('hostname');
fprintf('SERIAL REGION: hostname:%s\n', name)
p = parpool('4');
fprintf(' hostname numlabs labindex\n')
fprintf(' ------------------------------- ------- --------\n')
tic;
% PARALLEL REGION
spmd
[c name] = system('hostname');
name = name(1:length(name)-1);
fprintf('PARALLEL REGION: %-31s %7d %8d\n', name,numlabs,labindex)
pause(2);
end
% SERIAL REGION
elapsed_time = toc; % get elapsed time in parallel region
delete(p);
fprintf('\n')
[c name] = system('hostname');
name = name(1:length(name)-1);
fprintf('SERIAL REGION: hostname:%s\n', name)
fprintf('Elapsed time in parallel region: %f\n', elapsed_time)
quit;
Prepare a job submission file with an appropriate filename, here named myjob.sub. Run with the name of the script:
#!/bin/bash
# FILENAME: myjob.sub
echo "myjob.sub"
module load matlab
unset DISPLAY
matlab -nodisplay -r myscript
Run MATLAB to set the default parallel configuration to your job configuration:
$ matlab -nodisplay
>> parallel.defaultClusterProfile('myslurmprofile');
>> quit;
$
Once this job starts, a second job submission is made.
myjob.sub
< M A T L A B (R) >
Copyright 1984-2011 The MathWorks, Inc.
R2011b (7.13.0.564) 64-bit (glnxa64)
August 13, 2011
To get started, type one of these: helpwin, helpdesk, or demo.
For product information, visit www.mathworks.com.
SERIAL REGION: hostname:hammer-a001.rcac.purdue.edu
Starting matlabpool using the 'myslurmprofile' profile ... connected to 4 labs.
hostname numlabs labindex
------------------------------- ------- --------
Lab 2:
PARALLEL REGION: hammer-a002.rcac.purdue.edu 4 2
Lab 1:
PARALLEL REGION: hammer-a001.rcac.purdue.edu 4 1
Lab 3:
PARALLEL REGION: hammer-a003.rcac.purdue.edu 4 3
Lab 4:
PARALLEL REGION: hammer-a004.rcac.purdue.edu 4 4
Sending a stop signal to all the labs ... stopped.
SERIAL REGION: hostname:hammer-a001.rcac.purdue.edu
Elapsed time in parallel region: 3.382151
Output shows the name of one compute node (a001) that processed the job submission file myjob.sub and the two serial regions. The job submission scattered four processor cores (four MATLAB labs) among four different compute nodes (a001,a002,a003,a004) that processed the four parallel regions. The total elapsed time demonstrates that the jobs ran in parallel.
For more information about MATLAB Parallel Computing Toolbox:
Distributed Computing Server (parallel job)
The MATLAB Parallel Computing Toolbox (PCT) enables a parallel job via the MATLAB Distributed Computing Server (DCS). The tasks of a parallel job are identical, run simultaneously on several MATLAB workers (labs), and communicate with each other. This section illustrates an MPI-like program.
This section illustrates how to submit a small, MATLAB parallel job with four workers running one MPI-like task to a batch queue. The MATLAB program broadcasts an integer to four workers and gathers the names of the compute nodes running the workers and the lab IDs of the workers.
This example uses the job submission command to submit a Matlab script with a user-defined cluster profile which scatters the MATLAB workers onto different compute nodes. This method uses the MATLAB interpreter, the Parallel Computing Toolbox, and the Distributed Computing Server; so, it requires and checks out six licenses: one MATLAB license for the client running on the compute node, one PCT license, and four DCS licenses. Four DCS licenses run the four copies of the parallel job. This job is completely off the front end.
Prepare a MATLAB script named myscript.m :
% FILENAME: myscript.m
% Specify pool size.
% Convert the parallel job to a pool job.
parpool('4');
spmd
if labindex == 1
% Lab (rank) #1 broadcasts an integer value to other labs (ranks).
N = labBroadcast(1,int64(1000));
else
% Each lab (rank) receives the broadcast value from lab (rank) #1.
N = labBroadcast(1);
end
% Form a string with host name, total number of labs, lab ID, and broadcast value.
[c name] =system('hostname');
name = name(1:length(name)-1);
fmt = num2str(floor(log10(numlabs))+1);
str = sprintf(['%s:%d:%' fmt 'd:%d '], name,numlabs,labindex,N);
% Apply global concatenate to all str's.
% Store the concatenation of str's in the first dimension (row) and on lab #1.
result = gcat(str,1,1);
if labindex == 1
disp(result)
end
end % spmd
matlabpool close force;
quit;
Also, prepare a job submission, here named myjob.sub. Run with the name of the script:
# FILENAME: myjob.sub
echo "myjob.sub"
module load matlab
unset DISPLAY
# -nodisplay: run MATLAB in text mode; X11 server not needed
# -r: read MATLAB program; use MATLAB JIT Accelerator
matlab -nodisplay -r myscript
Run MATLAB to set the default parallel configuration to your appropriate Profile:
$ matlab -nodisplay
>> defaultParallelConfig('myslurmprofile');
>> quit;
$
Submit the job as a single compute node with one processor core.
Once this job starts, a second job submission is made.
myjob.sub
< M A T L A B (R) >
Copyright 1984-2011 The MathWorks, Inc.
R2011b (7.13.0.564) 64-bit (glnxa64)
August 13, 2011
To get started, type one of these: helpwin, helpdesk, or demo.
For product information, visit www.mathworks.com.
>Starting matlabpool using the 'myslurmprofile' configuration ... connected to 4 labs.
Lab 1:
hammer-a006.rcac.purdue.edu:4:1:1000
hammer-a007.rcac.purdue.edu:4:2:1000
hammer-a008.rcac.purdue.edu:4:3:1000
hammer-a009.rcac.purdue.edu:4:4:1000
Sending a stop signal to all the labs ... stopped.
Did not find any pre-existing parallel jobs created by matlabpool.
Output shows the name of one compute node (a006) that processed the job submission file myjob.sub. The job submission scattered four processor cores (four MATLAB labs) among four different compute nodes (a006,a007,a008,a009) that processed the four parallel regions.
To scale up this method to handle a real application, increase the wall time in the submission command to accommodate a longer running job. Secondly, increase the wall time of myslurmprofile by using the Cluster Profile Manager in the Parallel menu to enter a new wall time in the property SubmitArguments.
For more information about parallel jobs:
Python
Notice: Python 2.7 has reached end-of-life on Jan 1, 2020 (announcement). Please update your codes and your job scripts to use Python 3.
Python is a high-level, general-purpose, interpreted, dynamic programming language. We suggest using Anaconda which is a Python distribution made for large-scale data processing, predictive analytics, and scientific computing. For example, to use the default Anaconda distribution:
$ module load anaconda
For a full list of available Anaconda and Python modules enter:
$ module spider anaconda
Example Python Jobs
This section illustrates how to submit a small Python job to a PBS queue.
Link to section 'Example 1: Hello world' of 'Example Python Jobs' Example 1: Hello world
Prepare a Python input file with an appropriate filename, here named myjob.in:
# FILENAME: hello.py
import string, sys
print "Hello, world!"
Prepare a job submission file with an appropriate filename, here named myjob.sub:
#!/bin/bash
# FILENAME: myjob.sub
module load anaconda
python hello.py
Hello, world!Link to section 'Example 2: Matrix multiply' of 'Example Python Jobs' Example 2: Matrix multiply
Save the following script as matrix.py:
# Matrix multiplication program
x = [[3,1,4],[1,5,9],[2,6,5]]
y = [[3,5,8,9],[7,9,3,2],[3,8,4,6]]
result = [[sum(a*b for a,b in zip(x_row,y_col)) for y_col in zip(*y)] for x_row in x]
for r in result:
print(r)
Change the last line in the job submission file above to read:
python matrix.pyThe standard output file from this job will result in the following matrix:
[28, 56, 43, 53]
[65, 122, 59, 73]
[63, 104, 54, 60]
Link to section 'Example 3: Sine wave plot using numpy and matplotlib packages' of 'Example Python Jobs' Example 3: Sine wave plot using numpy and matplotlib packages
Save the following script as sine.py:
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pylab as plt
x = np.linspace(-np.pi, np.pi, 201)
plt.plot(x, np.sin(x))
plt.xlabel('Angle [rad]')
plt.ylabel('sin(x)')
plt.axis('tight')
plt.savefig('sine.png')
Change your job submission file to submit this script and the job will output a png file and blank standard output and error files.
For more information about Python:
Managing Environments with Conda
Conda is a package manager in Anaconda that allows you to create and manage multiple environments where you can pick and choose which packages you want to use. To use Conda you must load an Anaconda module:
$ module load anaconda
Many packages are pre-installed in the global environment. To see these packages:
$ conda list
To create your own custom environment:
$ conda create --name MyEnvName python=3.8 FirstPackageName SecondPackageName -y
The --name option specifies that the environment created will be named MyEnvName. You can include as many packages as you require separated by a space. Including the -y option lets you skip the prompt to install the package. By default environments are created and stored in the $HOME/.conda directory.
To create an environment at a custom location:
$ conda create --prefix=$HOME/MyEnvName python=3.8 PackageName -y
To see a list of your environments:
$ conda env list
To remove unwanted environments:
$ conda remove --name MyEnvName --all
To add packages to your environment:
$ conda install --name MyEnvName PackageNames
To remove a package from an environment:
$ conda remove --name MyEnvName PackageName
Installing packages when creating your environment, instead of one at a time, will help you avoid dependency issues.
To activate or deactivate an environment you have created:
$ source activate MyEnvName
$ source deactivate MyEnvName
If you created your conda environment at a custom location using --prefix option, then you can activate or deactivate it using the full path.
$ source activate $HOME/MyEnvName
$ source deactivate $HOME/MyEnvName
To use a custom environment inside a job you must load the module and activate the environment inside your job submission script. Add the following lines to your submission script:
$ module load anaconda
$ source activate MyEnvName
For more information about Python:
Managing Packages with Pip
Pip is a Python package manager. Many Python package documentation provide pip instructions that result in permission errors because by default pip will install in a system-wide location and fail.
Exception:
Traceback (most recent call last):
... ... stack trace ... ...
OSError: [Errno 13] Permission denied: '/apps/cent7/anaconda/2020.07-py38/lib/python3.8/site-packages/mkl_random-1.1.1.dist-info'
If you encounter this error, it means that you cannot modify the global Python installation. We recommend installing Python packages in a conda environment. Detailed instructions for installing packages with pip can be found in our Python package installation page.
Below we list some other useful pip commands.
- Search for a package in PyPI channels:
$ pip search packageName - Check which packages are installed globally:
$ pip list - Check which packages you have personally installed:
$ pip list --user - Snapshot installed packages:
$ pip freeze > requirements.txt - You can install packages from a snapshot inside a new conda environment. Make sure to load the appropriate conda environment first.
$ pip install -r requirements.txt
For more information about Python:
Installing Packages
Installing Python packages in an Anaconda environment is recommended. One key advantage of Anaconda is that it allows users to install unrelated packages in separate self-contained environments. Individual packages can later be reinstalled or updated without impacting others. If you are unfamiliar with Conda environments, please check our Conda Guide.
To facilitate the process of creating and using Conda environments, we support a script (conda-env-mod) that generates a module file for an environment, as well as an optional Jupyter kernel to use this environment in a JupyterHub notebook.
You must load one of the anaconda modules in order to use this script.
$ module load anacondaStep-by-step instructions for installing custom Python packages are presented below.
Link to section 'Step 1: Create a conda environment' of 'Installing Packages' Step 1: Create a conda environment
Users can use the conda-env-mod script to create an empty conda environment. This script needs either a name or a path for the desired environment. After the environment is created, it generates a module file for using it in future. Please note that conda-env-mod is different from the official conda-env script and supports a limited set of subcommands. Detailed instructions for using conda-env-mod can be found with the command conda-env-mod --help.
-
Example 1: Create a conda environment named mypackages in user's
$HOMEdirectory.$ conda-env-mod create -n mypackages -
Example 2: Create a conda environment named mypackages at a custom location.
$ conda-env-mod create -p /depot/mylab/apps/mypackagesPlease follow the on-screen instructions while the environment is being created. After finishing, the script will print the instructions to use this environment.
... ... ... Preparing transaction: ...working... done Verifying transaction: ...working... done Executing transaction: ...working... done +------------------------------------------------------+ | To use this environment, load the following modules: | | module load use.own | | module load conda-env/mypackages-py3.8.5 | +------------------------------------------------------+ Your environment "mypackages" was created successfully.
Note down the module names, as you will need to load these modules every time you want to use this environment. You may also want to add the module load lines in your jobscript, if it depends on custom Python packages.
By default, module files are generated in your $HOME/privatemodules directory. The location of module files can be customized by specifying the -m /path/to/modules option to conda-env-mod.
Note: The main differences between -p and -m are: 1) -p will change the location of packages to be installed for the env and the module file will still be located at the $HOME/privatemodules directory as defined in use.own. 2) -m will only change the location of the module file. So the method to load modules created with -m and -p are different, see Example 3 for details.
- Example 3: Create a conda environment named labpackages in your group's Data Depot space and place the module file at a shared location for the group to use.
$ conda-env-mod create -p /depot/mylab/apps/labpackages -m /depot/mylab/etc/modules ... ... ... Preparing transaction: ...working... done Verifying transaction: ...working... done Executing transaction: ...working... done +-------------------------------------------------------+ | To use this environment, load the following modules: | | module use /depot/mylab/etc/modules | | module load conda-env/labpackages-py3.8.5 | +-------------------------------------------------------+ Your environment "labpackages" was created successfully.
If you used a custom module file location, you need to run the module use command as printed by the command output above.
By default, only the environment and a module file are created (no Jupyter kernel). If you plan to use your environment in a JupyterHub notebook, you need to append a --jupyter flag to the above commands.
- Example 4: Create a Jupyter-enabled conda environment named labpackages in your group's Data Depot space and place the module file at a shared location for the group to use.
$ conda-env-mod create -p /depot/mylab/apps/labpackages -m /depot/mylab/etc/modules --jupyter ... ... ... Jupyter kernel created: "Python (My labpackages Kernel)" ... ... ... Your environment "labpackages" was created successfully.
Link to section 'Step 2: Load the conda environment' of 'Installing Packages' Step 2: Load the conda environment
-
The following instructions assume that you have used conda-env-mod script to create an environment named mypackages (Examples 1 or 2 above). If you used conda create instead, please use conda activate mypackages.
$ module load use.own $ module load conda-env/mypackages-py3.8.5Note that the conda-env module name includes the Python version that it supports (Python 3.8.5 in this example). This is same as the Python version in the anaconda module.
-
If you used a custom module file location (Example 3 above), please use module use to load the conda-env module.
$ module use /depot/mylab/etc/modules $ module load conda-env/labpackages-py3.8.5
Link to section 'Step 3: Install packages' of 'Installing Packages' Step 3: Install packages
Now you can install custom packages in the environment using either conda install or pip install.
Link to section 'Installing with conda' of 'Installing Packages' Installing with conda
-
Example 1: Install OpenCV (open-source computer vision library) using conda.
$ conda install opencv -
Example 2: Install a specific version of OpenCV using conda.
$ conda install opencv=4.5.5 -
Example 3: Install OpenCV from a specific anaconda channel.
$ conda install -c anaconda opencv
Link to section 'Installing with pip' of 'Installing Packages' Installing with pip
-
Example 4: Install pandas using pip.
$ pip install pandas -
Example 5: Install a specific version of pandas using pip.
$ pip install pandas==1.4.3Follow the on-screen instructions while the packages are being installed. If installation is successful, please proceed to the next section to test the packages.
Note: Do NOT run Pip with the --user argument, as that will install packages in a different location and might mess up your account environment.
Link to section 'Step 4: Test the installed packages' of 'Installing Packages' Step 4: Test the installed packages
To use the installed Python packages, you must load the module for your conda environment. If you have not loaded the conda-env module, please do so following the instructions at the end of Step 1.
$ module load use.own
$ module load conda-env/mypackages-py3.8.5
- Example 1: Test that OpenCV is available.
$ python -c "import cv2; print(cv2.__version__)" - Example 2: Test that pandas is available.
$ python -c "import pandas; print(pandas.__version__)"
If the commands finished without errors, then the installed packages can be used in your program.
Link to section 'Additional capabilities of conda-env-mod script' of 'Installing Packages' Additional capabilities of conda-env-mod script
The conda-env-mod tool is intended to facilitate creation of a minimal Anaconda environment, matching module file and optionally a Jupyter kernel. Once created, the environment can then be accessed via familiar module load command, tuned and expanded as necessary. Additionally, the script provides several auxiliary functions to help manage environments, module files and Jupyter kernels.
General usage for the tool adheres to the following pattern:
$ conda-env-mod help
$ conda-env-mod <subcommand> <required argument> [optional arguments]
where required arguments are one of
- -n|--name ENV_NAME (name of the environment)
- -p|--prefix ENV_PATH (location of the environment)
and optional arguments further modify behavior for specific actions (e.g. -m to specify alternative location for generated module files).
Given a required name or prefix for an environment, the conda-env-mod script supports the following subcommands:
- create - to create a new environment, its corresponding module file and optional Jupyter kernel.
- delete - to delete existing environment along with its module file and Jupyter kernel.
- module - to generate just the module file for a given existing environment.
- kernel - to generate just the Jupyter kernel for a given existing environment (note that the environment has to be created with a --jupyter option).
- help - to display script usage help.
Using these subcommands, you can iteratively fine-tune your environments, module files and Jupyter kernels, as well as delete and re-create them with ease. Below we cover several commonly occurring scenarios.
Note: When you try to use conda-env-mod delete, remember to include the arguments as you create the environment (i.e. -p package_location and/or -m module_location).
Link to section 'Generating module file for an existing environment' of 'Installing Packages' Generating module file for an existing environment
If you already have an existing configured Anaconda environment and want to generate a module file for it, follow appropriate examples from Step 1 above, but use the module subcommand instead of the create one. E.g.
$ conda-env-mod module -n mypackagesand follow printed instructions on how to load this module. With an optional --jupyter flag, a Jupyter kernel will also be generated.
Note that the module name mypackages should be exactly the same with the older conda environment name. Note also that if you intend to proceed with a Jupyter kernel generation (via the --jupyter flag or a kernel subcommand later), you will have to ensure that your environment has ipython and ipykernel packages installed into it. To avoid this and other related complications, we highly recommend making a fresh environment using a suitable conda-env-mod create .... --jupyter command instead.
Link to section 'Generating Jupyter kernel for an existing environment' of 'Installing Packages' Generating Jupyter kernel for an existing environment
If you already have an existing configured Anaconda environment and want to generate a Jupyter kernel file for it, you can use the kernel subcommand. E.g.
$ conda-env-mod kernel -n mypackagesThis will add a "Python (My mypackages Kernel)" item to the dropdown list of available kernels upon your next login to the JupyterHub.
Note that generated Jupiter kernels are always personal (i.e. each user has to make their own, even for shared environments). Note also that you (or the creator of the shared environment) will have to ensure that your environment has ipython and ipykernel packages installed into it.
Link to section 'Managing and using shared Python environments' of 'Installing Packages' Managing and using shared Python environments
Here is a suggested workflow for a common group-shared Anaconda environment with Jupyter capabilities:
The PI or lab software manager:
-
Creates the environment and module file (once):
$ module purge $ module load anaconda $ conda-env-mod create -p /depot/mylab/apps/labpackages -m /depot/mylab/etc/modules --jupyter -
Installs required Python packages into the environment (as many times as needed):
$ module use /depot/mylab/etc/modules $ module load conda-env/labpackages-py3.8.5 $ conda install ....... # all the necessary packages
Lab members:
-
Lab members can start using the environment in their command line scripts or batch jobs simply by loading the corresponding module:
$ module use /depot/mylab/etc/modules $ module load conda-env/labpackages-py3.8.5 $ python my_data_processing_script.py ..... -
To use the environment in Jupyter notebooks, each lab member will need to create his/her own Jupyter kernel (once). This is because Jupyter kernels are private to individuals, even for shared environments.
$ module use /depot/mylab/etc/modules $ module load conda-env/labpackages-py3.8.5 $ conda-env-mod kernel -p /depot/mylab/apps/labpackages
A similar process can be devised for instructor-provided or individually-managed class software, etc.
Link to section 'Troubleshooting' of 'Installing Packages' Troubleshooting
- Python packages often fail to install or run due to dependency incompatibility with other packages. More specifically, if you previously installed packages in your home directory it is safer to clean those installations.
$ mv ~/.local ~/.local.bak $ mv ~/.cache ~/.cache.bak - Unload all the modules.
$ module purge - Clean up PYTHONPATH.
$ unset PYTHONPATH - Next load the modules (e.g. anaconda) that you need.
$ module load anaconda/2020.11-py38 $ module load use.own $ module load conda-env/mypackages-py3.8.5 - Now try running your code again.
- Few applications only run on specific versions of Python (e.g. Python 3.6). Please check the documentation of your application if that is the case.
Installing Packages from Source
We maintain several Anaconda installations. Anaconda maintains numerous popular scientific Python libraries in a single installation. If you need a Python library not included with normal Python we recommend first checking Anaconda. For a list of modules currently installed in the Anaconda Python distribution:
$ module load anaconda
$ conda list
# packages in environment at /apps/spack/bell/apps/anaconda/2020.02-py37-gcc-4.8.5-u747gsx:
#
# Name Version Build Channel
_ipyw_jlab_nb_ext_conf 0.1.0 py37_0
_libgcc_mutex 0.1 main
alabaster 0.7.12 py37_0
anaconda 2020.02 py37_0
...
If you see the library in the list, you can simply import it into your Python code after loading the Anaconda module.
If you do not find the package you need, you should be able to install the library in your own Anaconda customization. First try to install it with Conda or Pip. If the package is not available from either Conda or Pip, you may be able to install it from source.
Use the following instructions as a guideline for installing packages from source. Make sure you have a download link to the software (usually it will be a tar.gz archive file). You will substitute it on the wget line below.
We also assume that you have already created an empty conda environment as described in our Python package installation guide.
$ mkdir ~/src
$ cd ~/src
$ wget http://path/to/source/tarball/app-1.0.tar.gz
$ tar xzvf app-1.0.tar.gz
$ cd app-1.0
$ module load anaconda
$ module load use.own
$ module load conda-env/mypackages-py3.8.5
$ python setup.py install
$ cd ~
$ python
>>> import app
>>> quit()
The "import app" line should return without any output if installed successfully. You can then import the package in your python scripts.
If you need further help or run into any issues installing a library, contact us or drop by Coffee Hour for in-person help.
For more information about Python:
Example: Create and Use Biopython Environment with Conda
Link to section 'Using conda to create an environment that uses the biopython package' of 'Example: Create and Use Biopython Environment with Conda' Using conda to create an environment that uses the biopython package
To use Conda you must first load the anaconda module:
module load anacondaCreate an empty conda environment to install biopython:
conda-env-mod create -n biopythonNow activate the biopython environment:
module load use.own
module load conda-env/biopython-py3.8.5Install the biopython packages in your environment:
conda install --channel anaconda biopython -y
Fetching package metadata ..........
Solving package specifications .........
.......
Linking packages ...
[ COMPLETE ]|################################################################
The --channel option specifies that it searches the anaconda channel for the biopython package. The -y argument is optional and allows you to skip the installation prompt. A list of packages will be displayed as they are installed.
Remember to add the following lines to your job submission script to use the custom environment in your jobs:
module load anaconda
module load use.own
module load conda-env/biopython-py3.8.5
If you need further help or run into any issues with creating environments, contact us or drop by Coffee Hour for in-person help.
For more information about Python:
Numpy Parallel Behavior
The widely available Numpy package is the best way to handle numerical computation in Python. The numpy package provided by our anaconda modules is optimized using Intel's MKL library. It will automatically parallelize many operations to make use of all the cores available on a machine.
In many contexts that would be the ideal behavior. On the cluster however that very likely is not in fact the preferred behavior because often more than one user is present on the system and/or more than one job on a node. Having multiple processes contend for those resources will actually result in lesser performance.
Setting the MKL_NUM_THREADS or OMP_NUM_THREADS environment variable(s) allows you to control this behavior. Our anaconda modules automatically set these variables to 1 if and only if you do not currently have that variable defined.
When submitting batch jobs it is always a good idea to be explicit rather than implicit. If you are submitting a job that you want to make use of the full resources available on the node, set one or both of these variables to the number of cores you want to allow numpy to make use of.
#!/bin/bash
module load anaconda
export MKL_NUM_THREADS=20
...
If you are submitting multiple jobs that you intend to be scheduled together on the same node, it is probably best to restrict numpy to a single core.
#!/bin/bash
module load anaconda
export MKL_NUM_THREADS=1
R
R, a GNU project, is a language and environment for data manipulation, statistics, and graphics. It is an open source version of the S programming language. R is quickly becoming the language of choice for data science due to the ease with which it can produce high quality plots and data visualizations. It is a versatile platform with a large, growing community and collection of packages.
For more general information on R visit The R Project for Statistical Computing.
Loading Data into R
R is an environment for manipulating data. In order to manipulate data, it must be brought into the R environment. R has a function to read any file that data is stored in. Some of the most common file types like comma-separated variable(CSV) files have functions that come in the basic R packages. Other less common file types require additional packages to be installed. To read data from a CSV file into the R environment, enter the following command in the R prompt:
> read.csv(file = "path/to/data.csv", header = TRUE)When R reads the file it creates an object that can then become the target of other functions. By default the read.csv() function will give the object the name of the .csv file. To assign a different name to the object created by read.csv enter the following in the R prompt:
> my_variable <- read.csv(file = "path/to/data.csv", header = FALSE)To display the properties (structure) of loaded data, enter the following:
> str(my_variable)For more functions and tutorials:
Running R jobs
This section illustrates how to submit a small R job to a SLURM queue. The example job computes a Pythagorean triple.
Prepare an R input file with an appropriate filename, here named myjob.R:
# FILENAME: myjob.R
# Compute a Pythagorean triple.
a = 3
b = 4
c = sqrt(a*a + b*b)
c # display result
Prepare a job submission file with an appropriate filename, here named myjob.sub:
#!/bin/bash
# FILENAME: myjob.sub
module load r
# --vanilla:
# --no-save: do not save datasets at the end of an R session
R --vanilla --no-save < myjob.R
For other examples or R jobs:
Installing R packages
Link to section 'Challenges of Managing R Packages in the Cluster Environment' of 'Installing R packages' Challenges of Managing R Packages in the Cluster Environment
- Different clusters have different hardware and softwares. So, if you have access to multiple clusters, you must install your R packages separately for each cluster.
- Each cluster has multiple versions of R and packages installed with one version of R may not work with another version of R. So, libraries for each R version must be installed in a separate directory.
- You can define the directory where your R packages will be installed using the environment variable
R_LIBS_USER. - For your convenience, a sample ~/.Rprofile example file is provided that can be downloaded to your cluster account and renamed into
~/.Rprofile(or appended to one) to customize your installation preferences. Detailed instructions.
Link to section 'Installing Packages' of 'Installing R packages' Installing Packages
-
Step 0: Set up installation preferences.
Follow the steps for setting up your~/.Rprofilepreferences. This step needs to be done only once. If you have created a~/.Rprofilefile previously on Hammer, ignore this step. -
Step 1: Check if the package is already installed.
As part of the R installations on community clusters, a lot of R libraries are pre-installed. You can check if your package is already installed by opening an R terminal and entering the commandinstalled.packages(). For example,module load r/4.1.2 Rinstalled.packages()["units",c("Package","Version")] Package Version "units" "0.6-3" quit()If the package you are trying to use is already installed, simply load the library, e.g.,
library('units'). Otherwise, move to the next step to install the package. -
Step 2: Load required dependencies. (if needed)
For simple packages you may not need this step. However, some R packages depend on other libraries. For example, thesfpackage depends ongdalandgeoslibraries. So, you will need to load the corresponding modules before installingsf. Read the documentation for the package to identify which modules should be loaded.module load gdal module load geos -
Step 3: Install the package.
Now install the desired package using the commandinstall.packages('package_name'). R will automatically download the package and all its dependencies from CRAN and install each one. Your terminal will show the build progress and eventually show whether the package was installed successfully or not.Rinstall.packages('sf', repos="https://cran.case.edu/") Installing package into ‘/home/myusername/R/hammer/4.0.0’ (as ‘lib’ is unspecified) trying URL 'https://cran.case.edu/src/contrib/sf_0.9-7.tar.gz' Content type 'application/x-gzip' length 4203095 bytes (4.0 MB) ================================================== downloaded 4.0 MB ... ... more progress messages ... ... ** testing if installed package can be loaded from final location ** testing if installed package keeps a record of temporary installation path * DONE (sf) The downloaded source packages are in ‘/tmp/RtmpSVAGio/downloaded_packages’ - Step 4: Troubleshooting. (if needed)
If Step 3 ended with an error, you need to investigate why the build failed. Most common reason for build failure is not loading the necessary modules.
Link to section 'Loading Libraries' of 'Installing R packages' Loading Libraries
Once you have packages installed you can load them with the library() function as shown below:
library('packagename')The package is now installed and loaded and ready to be used in R.
Link to section 'Example: Installing dplyr' of 'Installing R packages' Example: Installing dplyr
The following demonstrates installing the dplyr package assuming the above-mentioned custom ~/.Rprofile is in place (note its effect in the "Installing package into" information message):
module load r
Rinstall.packages('dplyr', repos="http://ftp.ussg.iu.edu/CRAN/")
Installing package into ‘/home/myusername/R/hammer/4.0.0’
(as ‘lib’ is unspecified)
...
also installing the dependencies 'crayon', 'utf8', 'bindr', 'cli', 'pillar', 'assertthat', 'bindrcpp', 'glue', 'pkgconfig', 'rlang', 'Rcpp', 'tibble', 'BH', 'plogr'
...
...
...
The downloaded source packages are in
'/tmp/RtmpHMzm9z/downloaded_packages'
library(dplyr)
Attaching package: 'dplyr'
For more information about installing R packages:
RStudio
RStudio is a graphical integrated development environment (IDE) for R. RStudio is the most popular environment for developing both R scripts and packages. RStudio is provided on most Research systems.
There are two methods to launch RStudio on the cluster: command-line and application menu icon.
Link to section 'Launch RStudio by the command-line:' of 'RStudio' Launch RStudio by the command-line:
module load gcc
module load r
module load rstudio
rstudioNote that RStudio is a graphical program and in order to run it you must have a local X11 server running or use Thinlinc Remote Desktop environment. See the ssh X11 forwarding section for more details.
Link to section 'Launch Rstudio by the application menu icon:' of 'RStudio' Launch Rstudio by the application menu icon:
- Log into desktop.hammer.rcac.purdue.edu with web browser or ThinLinc client
- Click on the
Applicationsdrop down menu on the top left corner - Choose
Cluster Softwareand thenRStudio
![]()
R and RStudio are free to download and run on your local machine. For more information about RStudio:
Link to section 'RStudio Server on Hammer' of 'Running RStudio Server on Hammer' RStudio Server on Hammer
A different version of RStudio is also installed on Hammer. RStudio Server allows you to run RStudio through your web browser.
Link to section 'Projects' of 'Running RStudio Server on Hammer' Projects
One benefit of RStudio is that your work can be separated into projects. You can give each project a working directory, workspace, history and source documents. When you are creating a new project, you can start it in a new empty directory, one with code and data already present or by cloning a repository.
RStudio Server allows easy collaboration and sharing of R projects. Just click on the project drop down menu in the top right corner and add the career account user names of those you wish to share with.
Link to section 'Sessions' of 'Running RStudio Server on Hammer' Sessions
Another feature is the ability to run multiple sessions at once. You can do multiple instances of the same project in parallel or work on different projects simultaneously. The sessions dropdown menu is in the upper right corner right above the project menu. Here you can kill or open sessions. Note that closing a window does not end a session, so please kill sessions when you are not using them.
You can view an overview of all your projects and active sessions by clicking on the blue RStudio Server Home logo in the top left corner of the window next to the file menu.
Link to section 'Packages' of 'Running RStudio Server on Hammer' Packages
You can install new packages with the install.packages() function in the console. You can also graphically select any packages you have previously installed on any cluster. Simply select packages from the tabs on the bottom right side of the window and select the package you wish to load.

For more information about RStudio:
Setting Up R Preferences with .Rprofile
For your convenience, a sample ~/.Rprofile example file is provided that can be downloaded to your cluster account and renamed into ~/.Rprofile (or appended to one). Follow these steps to download our recommended ~/.Rprofile example and copy it into place:
curl -#LO https://www.rcac.purdue.edu/files/knowledge/run/examples/apps/r/Rprofile_example
mv -ib Rprofile_example ~/.Rprofile
The above installation step needs to be done only once on Hammer. Now load the R module and run R:
module load r/4.1.2
R
.libPaths()
[1] "/home/myusername/R/hammer/4.1.2-gcc-6.3.0-ymdumss"
[2] "/apps/spack/hammer/apps/r/4.1.2-gcc-6.3.0-ymdumss/rlib/R/library"
.libPaths() should output something similar to above if it is set up correctly.
You are now ready to install R packages into the dedicated directory /home/myusername/R/hammer/4.1.2-gcc-6.3.0-ymdumss.
Spark
Apache Spark is an open-source data analytics cluster computing framework.
Hadoop
Spark is not tied to the two-stage MapReduce paradigm, and promises performance up to 100 times faster than Hadoop MapReduce for certain applications. Spark provides primitives for in-memory cluster computing that allows user programs to load data into a cluster's memory and query it repeatedly, making it well suited to machine learning algorithms.
Before to submit a Spark application to a YARN cluster, export environment variables:
$ source /etc/default/hadoop
To submit a Spark application to a YARN cluster:
$ cd /apps/hathi/spark
$ ./bin/spark-submit --master yarn --deploy-mode cluster examples/src/main/python/pi.py 100
Please note that there are two ways to specify the master: yarn-cluster and yarn-client. In cluster mode, your driver program will run on the worker nodes; while in client mode, your driver program will run within the spark-submit process which runs on the hathi front end. We recommand that you always use the cluster mode on hathi to avoid overloading the front end nodes.
To write your own spark jobs, use the Spark Pi as a baseline to start.
Spark can work with input files from both HDFS and local file system. The default after exporting the environment variables is from HDFS. To use input files that are on the cluster storage (e.g., data depot), specify: file:///path/to/file.
Note: when reading input files from cluster storage, the files must be accessible from any node in the cluster.
To run an interactive analysis or to learn the API with Spark Shell:
$ cd /apps/hathi/spark
$ ./bin/pyspark
Create a Resilient Distributed Dataset (RDD) from Hadoop InputFormats (such as HDFS files):
>>> textFile = sc.textFile("derby.log")
15/09/22 09:31:58 INFO storage.MemoryStore: ensureFreeSpace(67728) called with curMem=122343, maxMem=278302556
15/09/22 09:31:58 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 66.1 KB, free 265.2 MB)
15/09/22 09:31:58 INFO storage.MemoryStore: ensureFreeSpace(14729) called with curMem=190071, maxMem=278302556
15/09/22 09:31:58 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 14.4 KB, free 265.2 MB)
15/09/22 09:31:58 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:57813 (size: 14.4 KB, free: 265.4 MB)
15/09/22 09:31:58 INFO spark.SparkContext: Created broadcast 1 from textFile at NativeMethodAccessorImpl.java:-2
Note: derby.log is a file on hdfs://hathi-adm.rcac.purdue.edu:8020/user/myusername/derby.log
Call the count() action on the RDD:
>>> textFile.count()
15/09/22 09:32:01 INFO mapred.FileInputFormat: Total input paths to process : 1
15/09/22 09:32:01 INFO spark.SparkContext: Starting job: count at :1
15/09/22 09:32:01 INFO scheduler.DAGScheduler: Got job 0 (count at :1) with 2 output partitions (allowLocal=false)
15/09/22 09:32:01 INFO scheduler.DAGScheduler: Final stage: ResultStage 0(count at :1)
......
15/09/22 09:32:03 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 1870 bytes result sent to driver
15/09/22 09:32:04 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2254 ms on localhost (1/2)
15/09/22 09:32:04 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 2220 ms on localhost (2/2)
15/09/22 09:32:04 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/09/22 09:32:04 INFO scheduler.DAGScheduler: ResultStage 0 (count at :1) finished in 2.317 s
15/09/22 09:32:04 INFO scheduler.DAGScheduler: Job 0 finished: count at :1, took 2.548350 s
93
To learn programming in Spark, refer to Spark Programming Guide
To learn submitting Spark applications, refer to Submitting Applications
PBS
This section walks through how to submit and run a Spark job using PBS on the compute nodes of Hammer.
pbs-spark-submit launches an Apache Spark program within a PBS job, including starting the Spark master and worker processes in standalone mode, running a user supplied Spark job, and stopping the Spark master and worker processes. The Spark program and its associated services will be constrained by the resource limits of the job and will be killed off when the job ends. This effectively allows PBS to act as a Spark cluster manager.
The following steps assume that you have a Spark program that can run without errors.
To use Spark and pbs-spark-submit, you need to load the following two modules to setup SPARK_HOME and PBS_SPARK_HOME environment variables.
module load spark
module load pbs-spark-submit
The following example submission script serves as a template to build your customized, more complex Spark job submission. This job requests 2 whole compute nodes for 10 minutes, and submits to the default queue.
#PBS -N spark-pi
#PBS -l nodes=2:ppn=20
#PBS -l walltime=00:10:00
#PBS -q standby
#PBS -o spark-pi.out
#PBS -e spark-pi.err
cd $PBS_O_WORKDIR
module load spark
module load pbs-spark-submit
pbs-spark-submit $SPARK_HOME/examples/src/main/python/pi.py 1000
In the submission script above, this command submits the pi.py program to the nodes that are allocated to your job.
pbs-spark-submit $SPARK_HOME/examples/src/main/python/pi.py 1000
You can set various environment variables in your submission script to change the setting of Spark program. For example, the following line sets the SPARK_LOG_DIR to $HOME/log. The default value is current working directory.
export SPARK_LOG_DIR=$HOME/log
The same environment variables can be set via the pbs-spark-submit command line argument. For example, the following line sets the SPARK_LOG_DIR to $HOME/log2.
pbs-spark-submit --log-dir $HOME/log2
| Environment Variable | Default | Shell Export | Command Line Args |
|---|---|---|---|
| SPAKR_CONF_DIR | $SPARK_HOME/conf | export SPARK_CONF_DIR=$HOME/conf | --conf-dir |
| SPAKR_LOG_DIR | Current Working Directory | export SPARK_LOG_DIR=$HOME/log | --log-dir |
| SPAKR_LOCAL_DIR | /tmp | export SPARK_LOCAL_DIR=$RCAC_SCRATCH/local | NA |
| SCRATCHDIR | Current Working Directory | export SCRATCHDIR=$RCAC_SCRATCH/scratch | --work-dir |
| SPARK_MASTER_PORT | 7077 | export SPARK_MASTER_PORT=7078 | NA |
| SPARK_DAEMON_JAVA_OPTS | None | export SPARK_DAEMON_JAVA_OPTS="-Dkey=value" | -D key=value |
Note that SCRATCHDIR must be a shared scratch directory across all nodes of a job.
In addition, pbs-spark-submit supports command line arguments to change the properties of the Spark daemons and the Spark jobs. For example, the --no-stop argument tells Spark to not stop the master and worker daemons after the Spark application is finished, and the --no-init argument tells Spark to not initialize the Spark master and worker processes. This is intended for use in a sequence of invocations of Spark programs within the same job.
pbs-spark-submit --no-stop $SPARK_HOME/examples/src/main/python/pi.py 800
pbs-spark-submit --no-init $SPARK_HOME/examples/src/main/python/pi.py 1000
Use the following command to see the complete list of command line arguments.
pbs-spark-submit -h
To learn programming in Spark, refer to Spark Programming Guide
To learn submitting Spark applications, refer to Submitting Applications
Singularity
Note: Singularity was originally a project out of Lawrence Berkeley National Laboratory. It has now been spun off into a distinct offering under a new corporate entity under the name Sylabs Inc. This guide pertains to the open source community edition, SingularityCE.
Link to section 'What is Singularity?' of 'Singularity' What is Singularity?
Singularity is a new feature of the Community Clusters allowing the portability and reproducibility of operating system and application environments through the use of Linux containers. It gives users complete control over their environment.
Singularity is like Docker but tuned explicitly for HPC clusters. More information is available from the project’s website.
Link to section 'Features' of 'Singularity' Features
- Run the latest applications on an Ubuntu or Centos userland
- Gain access to the latest developer tools
- Launch MPI programs easily
- Much more
Singularity’s user guide is available at: sylabs.io/guides/3.8/user-guide
Link to section 'Example' of 'Singularity' Example
Here is an example using an Ubuntu 16.04 image on Hammer:
singularity exec /depot/itap/singularity/ubuntu1604.img cat /etc/lsb-release
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
DISTRIB_CODENAME=xenial
DISTRIB_DESCRIPTION="Ubuntu 16.04 LTS"
Here is another example using a Centos 7 image:
singularity exec /depot/itap/singularity/centos7.img cat /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
Link to section 'Purdue Cluster Specific Notes' of 'Singularity' Purdue Cluster Specific Notes
All service providers will integrate Singularity slightly differently depending on site. The largest customization will be which default files are inserted into your images so that routine services will work.
Services we configure for your images include DNS settings and account information. File systems we overlay into your images are your home directory, scratch, Data Depot, and application file systems.
Here is a list of paths:
- /etc/resolv.conf
- /etc/hosts
- /home/$USER
- /apps
- /scratch
- /depot
This means that within the container environment these paths will be present and the same as outside the container. The /apps, /scratch, and /depot directories will need to exist inside your container to work properly.
Link to section 'Creating Singularity Images' of 'Singularity' Creating Singularity Images
Due to how singularity containers work, you must have root privileges to build an image. Once you have a singularity container image built on your own system, you can copy the image file up to the cluster (you do not need root privileges to run the container).
You can find information and documentation for how to install and use singularity on your system:
We have version 3.8.0-1.el7 on the cluster. You will most likely not be able to run any container built with any singularity past that version. So be sure to follow the installation guide for version 3.8 on your system.
singularity --version
singularity version 3.8.0-1.el7
Everything you need on how to build a container is available from their user-guide. Below are merely some quick tips for getting your own containers built for Hammer.
You can use a Definition File to both build your container and share its specification with collaborators (for the sake of reproducibility). Here is a simplistic example of such a file:
# FILENAME: Buildfile
Bootstrap: docker
From: ubuntu:18.04
%post
apt-get update && apt-get upgrade -y
mkdir /apps /depot /scratch
To build the image itself:
sudo singularity build ubuntu-18.04.sif Buildfile
The challenge with this approach however is that it must start from scratch if you decide to change something. In order to create a container image iteratively and interactively, you can use the --sandbox option.
sudo singularity build --sandbox ubuntu-18.04 docker://ubuntu:18.04
This will not create a flat image file but a directory tree (i.e., a folder), the contents of which are the container's filesystem. In order to get a shell inside the container that allows you to modify it, user the --writable option.
sudo singularity shell --writable ubuntu-18.04
Singularity: Invoking an interactive shell within container...
Singularity ubuntu-18.04.sandbox:~>
You can then proceed to install any libraries, software, etc. within the container. Then to create the final image file, exit the shell and call the build command once more on the sandbox.
sudo singularity build ubuntu-18.04.sif ubuntu-18.04
Finally, copy the new image to Hammer and run it.
Windows
Windows virtual machines (VMs) are supported as batch jobs on HPC systems. This section illustrates how to submit a job and run a Windows instance in order to run Windows applications on the high-performance computing systems.
The following images are pre-configured and made available by staff:
- Windows 2016 Server Basic (minimal software pre-loaded)
- Windows 2016 Server GIS (GIS Software Stack pre-loaded)
The Windows VMs can be launched in two fashions:
- Menu Launcher - Point and click to start
- Command Line - Advanced and customized usage
Click each of the above links for detailed instructions on using them.
Link to section 'Software Provided in Pre-configured Virtual Machines' of 'Windows' Software Provided in Pre-configured Virtual Machines
The Windows 2016 Base server image available on Hammer has the following software packages preloaded:
- Anaconda Python 2 and Python 3
- JMP 13
- Matlab R2017b
- Microsoft Office 2016
- Notepad++
- NVivo 12
- Rstudio
- Stata SE 15
- VLC Media Player
The Windows 2016 GIS server image available on Hammer has the following software packages preloaded:
- ArcGIS Desktop 10.5
- ArcGIS Pro
- ArcGIS Server 10.5
- Anaconda Python 2 and Python 3
- ENVI5.3/IDL 8.5
- ERDAS Imagine
- GRASS GIS 7.4.0
- JMP 13
- Matlab R2017b
- Microsoft Office 2016
- Notepad++
- Pix4d Mapper
- QGIS Desktop
- Rstudio
- VLC Media Player
Command line
If you wish to work with Windows VMs on the command line or work into scripted workflows you can interact directly with the Windows system:
Copy a Windows 2016 Server VM image to your storage. Scratch or Research Data Depot are good locations to save a VM image. If you are using scratch, remember that scratch spaces are temporary, and be sure to safely back up your disk image somewhere permanent, such as Research Data Depot or Fortress. To copy a basic image:
$ cp /apps/external/apps/windows/images/latest.qcow2 $RCAC_SCRATCH/windows.qcow2
To copy a GIS image:
$ cp /depot/itap/windows/gis/2k16.qcow2 $RCAC_SCRATCH/windows.qcow2
To launch a virtual machine in a batch job, use the "windows" script, specifying the path to your Windows virtual machine image. With no other command-line arguments, the windows script will autodetect a number cores and memory for the Windows VM. A Windows network connection will be made to your home directory. To launch:
$ windows -i $RCAC_SCRATCH/windows.qcow2
Link to section 'Command line options:' of 'Command line' Command line options:
-i <path to qcow image file> (For example, $RCAC_SCRATCH/windows-2k16.qcow2)
-m <RAM>G (For example, 32G)
-c <cores> (For example, 20)
-s <smbpath> (UNIX Path to map as a drive, for example, $RCAC_SCRATCH)
-b (If present, launches VM in background. Use VNC to connect to Windows.)
To launch a virtual machine with 32GB of RAM, 20 cores, and a network mapping to your home directory:
$ windows -i /path/to/image.qcow2 -m 32G -c 20 -s $HOME
To launch a virtual machine with 16GB of RAM, 10 cores, and a network mapping to your Data Depot space:
$ windows -i /path/to/image.qcow2 -m 16G -c 10 -s /depot/mylab
The Windows 2016 server desktop will open, and automatically log in as an administrator, so that you can install any software into the Windows virtual machine that your research requires. Changes to the image will be stored in the file specified with the -i option.
Menu Launcher
Windows VMs can be easily launched through the login/thinlinc">Thinlinc remote desktop environment.
- Log in via login/thinlinc">Thinlinc.
- Click on Applications menu in the upper left corner.
- Look under the Cluster Software menu.
- The "Windows 10" launcher will launch a VM directly on the front-end.
- Follow the dialogs to set up your VM.
The dialog menus will walk you through setting up and loading your VM.
- You can choose to create a new image or load a saved image.
- New VMs should be saved on Scratch or Research Data Depot as they are too large for Home Directories.
- If you are using scratch, remember that scratch spaces are temporary, and be sure to safely back up your disk image somewhere permanent, such as Research Data Depot or Fortress.
You will also be prompted to select a storage space to mount on your image (Home, Scratch, or Data Depot). You can only choose one to be mounted. It will appear on a shortcut on the desktop once the VM loads.
Link to section 'Notes' of 'Menu Launcher' Notes
Using the menu launcher will launch automatically select reasonable CPU and memory values. If you wish to choose other options or work Windows VMs into scripted workflows see the section on using the command line.
Mathematica
Mathematica implements numeric and symbolic mathematics. This section illustrates how to submit a small Mathematica job to a PBS queue. This Mathematica example finds the three roots of a third-degree polynomial.
Prepare a Mathematica input file with an appropriate filename, here named myjob.in:
(* FILENAME: myjob.in *)
(* Find roots of a polynomial. *)
p=x^3+3*x^2+3*x+1
Solve[p==0]
Quit
Prepare a job submission file with an appropriate filename, here named myjob.sub:
#!/bin/sh -l # FILENAME: myjob.sub module load mathematica cd $PBS_O_WORKDIR math < myjob.in
Submit the job:
$ qsub -l nodes=1:ppn=20 myjob.sub
View job status:
$ qstat -u myusername
View results in the file for all standard output, here named myjob.sub.omyjobid:
Mathematica 5.2 for Linux x86 (64 bit)
Copyright 1988-2005 Wolfram Research, Inc.
-- Terminal graphics initialized --
In[1]:=
In[2]:=
In[2]:=
In[3]:=
2 3
Out[3]= 1 + 3 x + 3 x + x
In[4]:=
Out[4]= {{x -> -1}, {x -> -1}, {x -> -1}}
In[5]:=
View the standard error file, myjob.sub.emyjobid:
rmdir: ./ligo/rengel/tasks: Directory not empty
rmdir: ./ligo/rengel: Directory not empty
rmdir: ./ligo: Directory not empty
For more information about Mathematica:
Octave
GNU Octave is a high-level, interpreted, programming language for numerical computations. Octave is a structured language (similar to C) and mostly compatible with MATLAB. You may use Octave to avoid the need for a MATLAB license, both during development and as a deployed application. By doing so, you may be able to run your application on more systems or more easily distribute it to others.
This section illustrates how to submit a small Octave job to a PBS queue. This Octave example computes the inverse of a matrix.
Prepare an Octave script file with an appropriate filename, here named myjob.m:
% FILENAME: myjob.m
% Invert matrix A.
A = [1 2 3; 4 5 6; 7 8 0]
inv(A)
quit
Prepare a job submission file with an appropriate filename, here named myjob.sub:
#!/bin/sh -l
# FILENAME: myjob.sub
module load octave
cd $PBS_O_WORKDIR
unset DISPLAY
# Use the -q option to suppress startup messages.
# octave -q < myjob.m
octave < myjob.m
The command octave myjob.m (without the redirection) also works in the preceding script.
Submit the job:
$ qsub -l nodes=1:ppn=20 myjob.sub
View job status:
$ qstat -u myusername
View results in the file for all standard output, myjob.sub.omyjobid:
A =
1 2 3
4 5 6
7 8 0
ans =
-1.77778 0.88889 -0.11111
1.55556 -0.77778 0.22222
-0.11111 0.22222 -0.11111
Any output written to standard error will appear in myjob.sub.emyjobid.
For more information about Octave:
Using Jupyter Hub
Link to section 'What is Jupyter Hub' of 'Using Jupyter Hub' What is Jupyter Hub
Jupyter is an acronym meaning Julia, Python and R. The application was originally developed for use with these languages but now supports many more. Jupyter stores your project in a notebook. It is called a notebook because it is not just a block of code but rather a collection of information that relate to a project. The way you organize your notebook can explain processes and steps taken as well as highlight results. Notebooks provide a variety of formatting options while downloading so you can share the project appropriately for the situation. In addition, Jupyter can compile and run code, as well as save its output, making it an ideal workspace for many types of projects.
Jupyter Hub is currently available here or under the url https://notebook.hammer.rcac.purdue.edu.
Link to section 'Getting Started' of 'Using Jupyter Hub' Getting Started
When you are logging to Jupyter Hub on one of the clusters you need to use your career account credentials. After, you will see the contents of your home directory in a file explorer. To start a new notebook click the "New" dropdown menu at the right-top and select one of the kernels available. Bash, R or Python.
Link to section 'Create your own environment' of 'Using Jupyter Hub' Create your own environment
You can create your own environment in a kernel using a conda environment. Whatever environment you have created using conda can become in a Kernel ready to use in Jupyter Hub, just following some steps in the terminal or from the conda tab in the Jupyter Hub dashboard.
Below are listed the steps needed to create the environment for Jupyter from the terminal.
-
Load the anaconda module or use your own local installation.
$ module load anaconda/5.1.0-py36 -
Create your own Conda environment with the following packages.
$ conda create -n MyEnvName ipython ipykernel [...more-needed-packages...](and if you need a specific Python version in your environment, you can also add a
python=x.yspecification to the above command). -
Activate your environment.
$ source activate MyEnvName -
Install the new Kernel.
$ ipython kernel install --user --name MyEnvName --display-name "Python (My Own MyEnvName Kernel)"The
--namevalue is used by Jupyter internally. These commands will overwrite any existing kernel with the same name.--display-nameis what you see in the notebook menus. - Go to your Jupyter dashboard and reload the page, you will see your own Kernel when you create a new Notebook. If you want to change the Kernel in the current Notebook, just go to the Kernel tab and select it from the "Change Kernel" option.
If you want to create the environment from the Dashboard, just go to the conda tab and create a new one with one of the available kernels, it will take some minutes while all base packages are being installed, after the new environment shows up in the list you can just select the libraries you want from the box under the list.

Additionally, You can change the environment you are using at any time by clicking the "Kernel" dropdown menu and selecting "Change kernel".
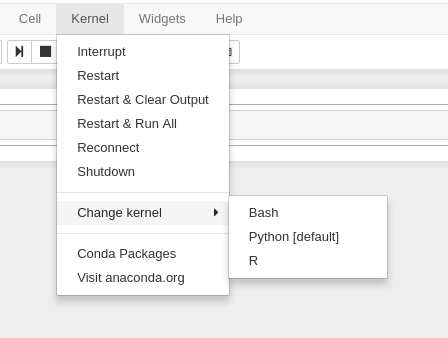
If you want to install a new kernel different from Python (e.g. R or Bash), please refer to the links at the end.
To run code in a cell, select the cell and click the "run cell" icon on the toolbar.
To add descriptions or other plain text change the cell to markdown format. Any standard markdown tags will apply after you click the "run cell" tool.
Below is a simple example of a notebook created following the steps outlined above.
For more information about Jupyter Hub, kernels and example notebooks:
Frequently Asked Questions
Some common questions, errors, and problems are categorized below. Click the Expand Topics link in the upper right to see all entries at once. You can also use the search box above to search the user guide for any issues you are seeing.
About Hammer
Frequently asked questions about Hammer.
Can you remove me from the Hammer mailing list?
Your subscription in the Hammer mailing list is tied to your account on Hammer. If you are no longer using your account on Hammer, your account can be deleted from the My Accounts page. Hover over the resource you wish to remove yourself from and click the red 'X' button. Your account and mailing list subscription will be removed overnight. Be sure to make a copy of any data you wish to keep first.
How is Hammer different than other Community Clusters?
- Hammer is optimized for loosely-coupled, high-throughput computation. The scheduler is configured to favor starting jobs quickly and ensure maximum utilization.
- The maximum job size is 8 processor cores. If you require resources with a greater degree of parallelism, please consider an alternate community cluster system optimized for high-performance, parallel computing.
- Jobs are scheduled on a whole-node basis and will not share nodes with other jobs by default. You may submit jobs that use less than one node, however, you will be allocated a whole node from your queue unless node sharing is enabled. Node sharing is enabled by adding ‑l naccesspolicy=singleuser to your job's requirements.
Do I need to do anything to my firewall to access Hammer?
No firewall changes are needed to access Hammer. However, to access data through Network Drives (i.e., CIFS, "Z: Drive"), you must be on a Purdue campus network or connected through VPN.
Logging In & Accounts
Frequently asked questions about logging in & accounts.
Errors
Common errors and solutions/work-arounds for them.
/usr/bin/xauth: error in locking authority file
Link to section 'Problem' of '/usr/bin/xauth: error in locking authority file' Problem
I receive this message when logging in:
/usr/bin/xauth: error in locking authority file
Link to section 'Solution' of '/usr/bin/xauth: error in locking authority file' Solution
Your home directory disk quota is full. You may check your quota with myquota.
You will need to free up space in your home directory.
ncdu command is a convenient interactive tool to examine disk usage. Consider running ncdu $HOME to analyze where the bulk of the usage is. With this knowledge, you could then archive your data elsewhere (e.g. your research group's Data Depot space, or Fortress tape archive), or delete files you no longer need.
There are several common locations that tend to grow large over time and are merely cached downloads. The following are safe to delete if you see them in the output of ncdu $HOME:
/home/myusername/.local/share/Trash
/home/myusername/.cache/pip
/home/myusername/.conda/pkgs
/home/myusername/.singularity/cache
My SSH connection hangs
Link to section 'Problem' of 'My SSH connection hangs' Problem
Your console hangs while trying to connect to a RCAC Server.
Link to section 'Solution' of 'My SSH connection hangs' Solution
This can happen due to various reasons. Most common reasons for hanging SSH terminals are:
- Network: If you are connected over wifi, make sure that your Internet connection is fine.
- Busy front-end server: When you connect to a cluster, you SSH to one of the front-end login nodes. Due to transient user loads, one or more of the front-ends may become unresponsive for a short while. To avoid this, try reconnecting to the cluster or wait until the login node you have connected to has reduced load.
- File system issue: If a server has issues with one or more of the file systems (
home,scratch, ordepot) it may freeze your terminal. To avoid this you can connect to another front-end.
If neither of the suggestions above work, please contact support specifying the name of the server where your console is hung.
Thinlinc session frozen
Link to section 'Problem' of 'Thinlinc session frozen' Problem
Your Thinlinc session is frozen and you can not launch any commands or close the session.
Link to section 'Solution' of 'Thinlinc session frozen' Solution
This can happen due to various reasons. The most common reason is that you ran something memory-intensive inside that Thinlinc session on a front-end, so parts of the Thinlinc session got killed by Cgroups, and the entire session got stuck.
- If you are using a web-version Thinlinc remote desktop (inside the browser):
The web version does not have the capability to kill the existing session, only the standalone client does. Please install the standalone client and follow the steps below:
- If you are using a Thinlinc client:
Close the ThinLinc client, reopen the client login popup, and select
End existing session.
Select "End existing session" and try "Connect" again.
Thinlinc session unreachable
Link to section 'Problem' of 'Thinlinc session unreachable' Problem
When trying to login to Thinlinc and re-connect to your existing session, you receive an error "Your Thinlinc session is currently unreachable".
Link to section 'Solution' of 'Thinlinc session unreachable' Solution
This can happen if the specific login node your existing remote desktop session was residing on is currently offline or down, so Thinlinc can not reconnect to your existing session. Most often the session is non-recoverable at this point, so the solution is to terminate your existing Thinlinc desktop session and start a new one.
- If you are using a web-version Thinlinc remote desktop (inside the browser):
The web version does not have the capability to kill the existing session, only the standalone client does. Please install the standalone client and follow the steps below:
- If you are using a Thinlinc client:
Close the ThinLinc client, reopen the client login popup, and select
End existing session.
Select "End existing session" and try "Connect" again.
Questions
Frequently asked questions about logging in & accounts.
I worked on Hammer after I graduated/left Purdue, but can not access it anymore
Link to section 'Problem' of 'I worked on Hammer after I graduated/left Purdue, but can not access it anymore' Problem
You have graduated or left Purdue but continue collaboration with your Purdue colleagues. You find that your access to Purdue resources has suddenly stopped and your password is no longer accepted.
Link to section 'Solution' of 'I worked on Hammer after I graduated/left Purdue, but can not access it anymore' Solution
Access to all resources depends on having a valid Purdue Career Account. Expired Career Accounts are removed twice a year, during Spring and October breaks (more details at the official page). If your Career Account was purged due to expiration, you will not be be able to access the resources.
To provide remote collaborators with valid Purdue credentials, the University provides a special procedure called Request for Privileges (R4P). If you need to continue your collaboration with your Purdue PI, the PI will have to submit or renew an R4P request on your behalf.
After your R4P is completed and Career Account is restored, please note two additional necessary steps:
-
Access: Restored Career Accounts by default do not have any RCAC resources enabled for them. Your PI will have to login to the Manage Users tool and explicitly re-enable your access by un-checking and then ticking back checkboxes for desired queues/Unix groups resources.
-
Email: Restored Career Accounts by default do not have their @purdue.edu email service enabled. While this does not preclude you from using RCAC resources, any email messages (be that generated on the clusters, or any service announcements) would not be delivered - which may cause inconvenience or loss of compute jobs. To avoid this, we recommend setting your restored @purdue.edu email service to "Forward" (to an actual address you read). The easiest way to ensure it is to go through the Account Setup process.
Jobs
Frequently asked questions related to running jobs.
Errors
Common errors and potential solutions/workarounds for them.
cannot connect to X server / cannot open display
Link to section 'Problem' of 'cannot connect to X server / cannot open display' Problem
You receive the following message after entering a command to bring up a graphical window
cannot connect to X server
cannot open display
Link to section 'Solution' of 'cannot connect to X server / cannot open display' Solution
This can happen due to multiple reasons:
- Reason: Your SSH client software does not support graphical display by itself (e.g. SecureCRT or PuTTY).
- Solution: Try using a client software like Thinlinc or MobaXterm as described in the SSH X11 Forwarding guide.
-
Reason: You did not enable X11 forwarding in your SSH connection.
-
Solution: If you are in a Windows environment, make sure that X11 forwarding is enabled in your connection settings (e.g. in MobaXterm or PuTTY). If you are in a Linux environment, try
ssh -Y -l username hostname
-
- Reason: If you are trying to open a graphical window within an interactive PBS job, make sure you are using the
-Xoption withqsubafter following the previous step(s) for connecting to the front-end. Please see the example in the Interactive Jobs guide. - Reason: If none of the above apply, make sure that you are within quota of your home directory.
bash: command not found
Link to section 'Problem' of 'bash: command not found' Problem
You receive the following message after typing a command
bash: command not found
Link to section 'Solution' of 'bash: command not found' Solution
This means the system doesn't know how to find your command. Typically, you need to load a module to do it.
qdel: Server could not connect to MOM 12345.hammer-adm.rcac.purdue.edu
Link to section 'Problem' of 'qdel: Server could not connect to MOM 12345.hammer-adm.rcac.purdue.edu' Problem
You receive the following message after attempting to delete a job with the qdel command
qdel: Server could not connect to MOM 12345.hammer-adm.rcac.purdue.edu
Link to section 'Solution' of 'qdel: Server could not connect to MOM 12345.hammer-adm.rcac.purdue.edu' Solution
This error usually indicates that at least one node running your job has stopped responding or crashed. Please forward the job ID to support, and staff can help remove the job from the queue.
bash: module command not found
Link to section 'Problem' of 'bash: module command not found' Problem
You receive the following message after typing a command, e.g. module load intel
bash: module command not found
Link to section 'Solution' of 'bash: module command not found' Solution
The system cannot find the module command. You need to source the modules.sh file as below
source /etc/profile.d/modules.sh
or
#!/bin/bash -i
1234.hammer-adm.rcac.purdue.edu.SC: line 12: 12345 Killed
Link to section 'Problem' of '1234.hammer-adm.rcac.purdue.edu.SC: line 12: 12345 Killed' Problem
Your PBS job stopped running and you received an email with the following:
/var/spool/torque/mom_priv/jobs/1234.hammer-adm.rcac.purdue.edu.SC: line 12: 12345 Killed <command name>Link to section 'Solution' of '1234.hammer-adm.rcac.purdue.edu.SC: line 12: 12345 Killed' Solution
This means that the node your job was running on ran out of memory to support your program or code. This may be due to your job or other jobs sharing your node(s) consuming more memory in total than is available on the node. Your program was killed by the node to preserve the operating system. There are two possible causes:
- You requested your job share node(s) with other jobs. You should request all cores of the node or request exclusive access. Either your job or one of the other jobs running on the node consumed too much memory. Requesting exclusive access will give you full control over all the memory on the node.
- Your job requires more memory than is available on the node. You should use more nodes if your job supports MPI or run a smaller dataset.
Questions
Frequently asked questions about jobs.
How do I check my job output while it is running?
Link to section 'Problem' of 'How do I check my job output while it is running?' Problem
After submitting your job to the cluster, you want to see the output that it generates.
Link to section 'Solution' of 'How do I check my job output while it is running?' Solution
There are two simple ways to do this:
- qpeek: Use the tool qpeek to check the job's output. Syntax of the command is:
qpeek <jobid> - Redirect your output to a file: To do this you need to edit the main command in your jobscript as shown below. Please note the redirection command starting with the greater than (>) sign.
On any front-end, go to the working directory of the job and scan the output file.myapplication ...other arguments... > "${PBS_JOBID}.output"
Make sure to replace <jobid> with an appropriate jobid.tail "<jobid>.output"
What is the "debug" queue?
The debug queue allows you to quickly start small, short, interactive jobs in order to debug code, test programs, or test configurations. You are limited to one running job at a time in the queue, and you may run up to two compute nodes for 30 minutes.
How can I get email alerts about my PBS job status?
Link to section 'Question' of 'How can I get email alerts about my PBS job status?' Question
How can I be notified when my PBS job was executed and if it completed successfully?
Link to section 'Answer' of 'How can I get email alerts about my PBS job status?' Answer
Submit your job with the following command line arguments
qsub -M email_address -m bea myjobsubmissionfileOr, include the following in your job submission file.
#PBS -M email_address
#PBS -m bae
The -m option can have the following letters; "a", "b", and "e":
a - mail is sent when the job is aborted by the batch system.
b - mail is sent when the job begins execution.
e - mail is sent when the job terminates.
Can I extend the walltime on a job?
In some circumstances, yes. Walltime extensions must be requested of and completed by staff. Walltime extension requests will be considered on named (your advisor or research lab) queues. Standby or debug queue jobs cannot be extended.
Extension requests are at the discretion of staff based on factors such as any upcoming maintenance or resource availability. Extensions can be made past the normal maximum walltime on named queues but these jobs are subject to early termination should a conflicting maintenance downtime be scheduled.
Please be mindful of time remaining on your job when making requests and make requests at least 24 hours before the end of your job AND during business hours. We cannot guarantee jobs will be extended in time with less than 24 hours notice, after-hours, during weekends, or on a holiday.
We ask that you make accurate walltime requests during job submissions. Accurate walltimes will allow the job scheduler to efficiently and quickly schedule jobs on the cluster. Please consider that extensions can impact scheduling efficiency for all users of the cluster.
Requests can be made by contacting support. We ask that you:
- Provide numerical job IDs, cluster name, and your desired extension amount.
- Provide at least 24 hours notice before job will end (more if request is made on a weekend or holiday).
- Consider making requests during business hours. We may not be able to respond in time to requests made after-hours, on a weekend, or on a holiday.
How do I know Non-uniform Memory Access (NUMA) layout on Hammer?
- You can learn about processor layout on Hammer nodes using the following command:
hammer-a003:~$ lstopo-no-graphics - For detailed IO connectivity:
hammer-a003:~$ lstopo-no-graphics --physical --whole-io - Please note that NUMA information is useful for advanced MPI/OpenMP/GPU optimizations. For most users, using default NUMA settings in MPI or OpenMP would give you the best performance.
Why cannot I use --mem=0 when submitting jobs?
Link to section 'Question' of 'Why cannot I use --mem=0 when submitting jobs?' Question
Why can't I specify --mem=0 for my job?
Link to section 'Answer' of 'Why cannot I use --mem=0 when submitting jobs?' Answer
We no longer support requesting unlimited memory (--mem=0) as it has an adverse effect on the way scheduler allocates job, and could lead to large amount of nodes being blocked from usage.
Most often we suggest relying on default memory allocation (cluster-specific). But if you have to request custom amounts of memory, you can do it explicitly. For example --mem=20G.
If you want to use the entire node's memory, you can submit the job with the --exclusive option.
Data
Frequently asked questions about data and data management.
My scratch files were purged. Can I retrieve them?
Unfortunately, once files are purged, they are purged permanently and cannot be retrieved. Notices of pending purges are sent one week in advance to your Purdue email address. Be sure to regularly check your Purdue email or set up forwarding to an account you do frequently check.
Link to section 'Can you tell me what files were purged?' of 'My scratch files were purged. Can I retrieve them?' Can you tell me what files were purged?
You can see a list of files removed with the command lastpurge. The command accepts a -n option to specify how many weeks/purges ago you want to look back at.
How is my Data Secured on Hammer?
Hammer is operated in line with policies, standards, and best practices as described within Secure Purdue, and specific to RCAC Resources.
Security controls for Hammer are based on ones defined in NIST cybersecurity standards.
Hammer supports research at the L1 fundamental and L2 sensitive levels. Hammer is not approved for storing data at the L3 restricted (covered by HIPAA) or L4 Export Controlled (ITAR), or any Controlled Unclassified Information (CUI).
For resources designed to support research with heightened security requirements, please look for resources within the REED+ Ecosystem.
Link to section 'For additional information' of 'How is my Data Secured on Hammer?' For additional information
Log in with your Purdue Career Account.
Can I share data with outside collaborators?
Yes! Globus allows convenient sharing of data with outside collaborators. Data can be shared with collaborators' personal computers or directly with many other computing resources at other institutions. See the Globus documentation on how to share data:
Can I access Fortress from Hammer?
Yes. While Fortress directories are not directly mounted on Hammer for performance and archival protection reasons, they can be accessed from Hammer front-ends and nodes using any of the recommended methods of HSI, HTAR or Globus.
Software
Frequently asked questions about software.
Cannot use pip after loading ml-toolkit modules
Link to section 'Question' of 'Cannot use pip after loading ml-toolkit modules' Question
Pip throws an error after loading the machine learning modules. How can I fix it?
Link to section 'Answer' of 'Cannot use pip after loading ml-toolkit modules' Answer
Machine learning modules (tensorflow, pytorch, opencv etc.) include a version of pip that is newer than the one installed with Anaconda. As a result it will throw an error when you try to use it.
$ pip --version
Traceback (most recent call last):
File "/apps/cent7/anaconda/5.1.0-py36/bin/pip", line 7, in <module>
from pip import main
ImportError: cannot import name 'main'
The preferred way to use pip with the machine learning modules is to invoke it via Python as shown below.
$ python -m pip --versionHow can I get access to Sentaurus software?
Link to section 'Question' of 'How can I get access to Sentaurus software?' Question
How can I get access to Sentaurus tools for micro- and nano-electronics design?
Link to section 'Answer' of 'How can I get access to Sentaurus software?' Answer
Sentaurus software license requires a signed NDA. Please contact Dr. Mark Johnson, Director of ECE Instructional Laboratories to complete the process.
Once the licensing process is complete and you have been added into a cae2 Unix group, you could use Sentaurus on RCAC community clusters by loading the corresponding environment module:
module load sentaurusAbout Research Computing
Frequently asked questions about RCAC.
Can I get a private server from RCAC?
Link to section 'Question' of 'Can I get a private server from RCAC?' Question
Can I get a private (virtual or physical) server from RCAC?
Link to section 'Answer' of 'Can I get a private server from RCAC?' Answer
Often, researchers may want a private server to run databases, web servers, or other software. RCAC currently has Geddes, a Community Composable Platform optimized for composable, cloud-like workflows that are complementary to the batch applications run on Community Clusters. Funded by the National Science Foundation under grant OAC-2018926, Geddes consists of Dell Compute nodes with two 64-core AMD Epyc 'Rome' processors (128 cores per node).
To purchase access to Geddes today, go to the Cluster Access Purchase page. Please subscribe to our Community Cluster Program Mailing List to stay informed on the latest purchasing developments or contact us (rcac-cluster-purchase@lists.purdue.edu) if you have any questions.
Gateway (OnDemand)
Hammer's Gateway is an open-source HPC portal developed by the Ohio Supercomputing Center. Open OnDemand allows one to interact with HPC resources through a web browser and easily manage files, submit jobs, and interact with graphical applications directly in a browser, all with no software to install. Hammer has an instance of OnDemand available that can be accessed via gateway.hammer.rcac.purdue.edu.
Link to section 'Logging In' of 'Gateway (OnDemand)' Logging In
To log into Gateway:
- Navigate to gateway.hammer.rcac.purdue.edu
- Log in using your Purdue Login