
RCAC student improves Anvil supercomputer while obtaining Master’s degree
Vivek Karunai Kiri Ragavan, a Graduate Research Assistant at the Rosen Center for Advanced Computing (RCAC), recently obtained his Master of Science (MS) degree in Computer Information and Technology. His MS thesis was related to the work he conducted at RCAC, which focused on enhancing cloud-native clusters through custom scheduling.
Ragavan began  working at RCAC in the autumn of 2023 as part of the center’s CI-XP student program. Prior to enrollment in his Master’s program, Ragavan worked for three years at Cisco Systems as a software consulting engineer. When deciding on a part-time job to take while he completed his studies at Purdue, Ragavan knew he wanted to work in the software engineering field where he could stay relevant to his old job while learning something new. RCAC provided the perfect opportunity to do just that.
working at RCAC in the autumn of 2023 as part of the center’s CI-XP student program. Prior to enrollment in his Master’s program, Ragavan worked for three years at Cisco Systems as a software consulting engineer. When deciding on a part-time job to take while he completed his studies at Purdue, Ragavan knew he wanted to work in the software engineering field where he could stay relevant to his old job while learning something new. RCAC provided the perfect opportunity to do just that.
“I was searching for a job where I could stay in touch with the type of work that I was doing at Cisco,” says Ragavan. “Two friends told me about RCAC, which intrigued me. After being admitted to Purdue, I began emailing RCAC research scientists, which led to me securing an interview with Sarah [Rodenbeck], and later, with Erik [Gough]. So it was this really cool experience where I was able to still do this job that I love while learning something new.”
For his Master’s thesis, Ragavan focused on two significant projects, both related to developing custom scheduling capabilities within the Kubernetes Control Plane. Kubernetes is an open-source container orchestration tool that is widely used in the computing industry. It automates the deployment, scaling, and management of containerized applications (software applications that are packaged within stand-alone containers, which include everything needed to run said software). In essence, Kubernetes enables developers to focus on building their software instead of needing to understand and manage the underlying infrastructure required for successful implementation. But there was one issue that Ragavan noticed with Kubernetes—it did not account for network performance when making orchestration decisions, resulting in performance slowdowns.
“So one major drawback with Kubernetes,” says Ragavan, “is that it considers only CPU and memory, which are the default resource constraints. It does not take into consideration the network performance or the current network situation in the cluster. So that leaves a big gap where if we try to schedule or host applications that are latency sensitive and that are expecting high-speed performance between the containers, we basically start having issues. We start to see delays and performance degradation because the pods are placed in different nodes, and Kubernetes is not factoring in all of the potential network constraints.”
Tackling this issue 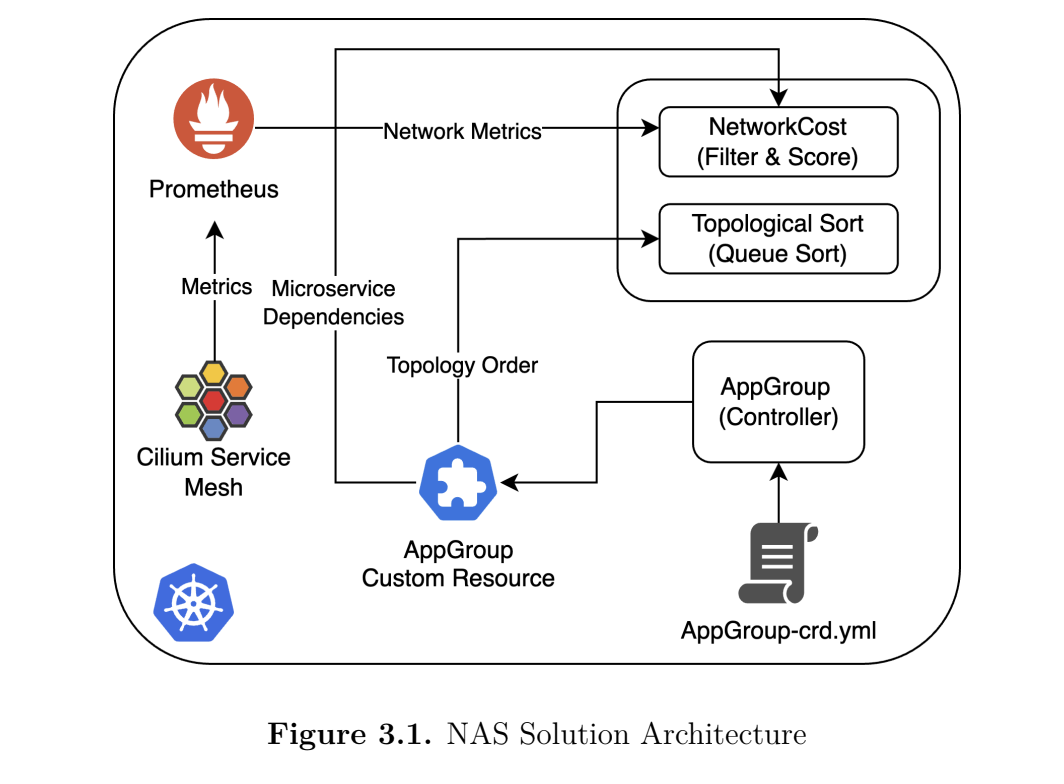 was the first part of Ragavan’s MS thesis. His goal was to develop and implement a network-aware scheduler into Kubernetes that considers factors such as latency and bandwidth. Ragavan began by integrating an eBPF-based service mesh to collect network performance metrics. He then developed his own “network cost” plugin that could be added to multiple extension points in the Kubernetes scheduling framework. This plugin enables Kubernetes to factor in the network cost metrics when organizing the placement of pods (pod=group of containers) across cluster nodes. By optimizing pod placement based on network metrics, latency is reduced and application performance is improved. Ragavan’s solution turned out to be extremely successful. He found that his new network-aware scheduler reduced average latency by nearly 53% and minimized maximum latency spikes by 85% compared to the default Kubernetes scheduler. In fact, Ragavan’s work was substantial enough to be accepted for the 2025 IEEE International Conference on Communications in Montreal, Canada, where he presented alongside his academic advisor, Dr. Deepak Nadig, on June 9.
was the first part of Ragavan’s MS thesis. His goal was to develop and implement a network-aware scheduler into Kubernetes that considers factors such as latency and bandwidth. Ragavan began by integrating an eBPF-based service mesh to collect network performance metrics. He then developed his own “network cost” plugin that could be added to multiple extension points in the Kubernetes scheduling framework. This plugin enables Kubernetes to factor in the network cost metrics when organizing the placement of pods (pod=group of containers) across cluster nodes. By optimizing pod placement based on network metrics, latency is reduced and application performance is improved. Ragavan’s solution turned out to be extremely successful. He found that his new network-aware scheduler reduced average latency by nearly 53% and minimized maximum latency spikes by 85% compared to the default Kubernetes scheduler. In fact, Ragavan’s work was substantial enough to be accepted for the 2025 IEEE International Conference on Communications in Montreal, Canada, where he presented alongside his academic advisor, Dr. Deepak Nadig, on June 9.
The second part of Ragavan’s MS thesis focused on developing GPU (graphics processing unit) autoscaling mechanisms based on real-time demand. This project was targeted at improving the performance and efficiency of AnvilGPT, RCAC’s large language model (LLM) service that makes open-source LLM models like LLaMA accessible worldwide to ACCESS researchers. AnvilGPT utilizes cutting-edge NVIDIA H100 GPUs to provide these LLM models to researchers. Such advanced GPUs are precious commodities—i.e., they should be carefully managed to avoid frivolous allocation. In the instance of AnvilGPT, the research software engineers (RSEs) at RCAC currently have a maximum limit of three GPUs that can be allocated at any given time to the service. However, the real-time demands of AnvilGPT varies, and utilizing three full GPUs during periods of low activity is not ideal. What RCAC needed was for Kubernetes to automatically scale the amount of GPU resources based on current system conditions, an objective that Ragavan sought to achieve with the second half of his MS thesis.
Kubernetes already has a tool called HorizontalPodAutoscaler (HPA), which, as the name suggests, automatically scales the workload horizontally. The problem—much like in his first project—is that it adjusts resources to match observed utilization based only on CPU, GPU, or memory usage, which does not accurately represent the model workload or user demand for LLM services like AnvilGPT. Ragavan needed to implement a system that considered real-time inference workload metrics. His first step was to benchmark the most popular models used across AnvilGPT, which were Llama 3.1 8B and Llama 3.1 70B.
“So first, I started benchmarking these models,” says Ragavan, “to try and understand how each of them were used by the researchers and what kind of resources were required for the particular model to run in a fashion that is acceptable as a chat application.”
Ragavan continues, “When you use an LLM model and make a query, it ends up being more like a chat application, right? And when using it, you expect a response to come within milliseconds to seconds, so that it remains more like a conversation. But if you are having to wait 25 to 30 seconds for a response, you’ll get very frustrated. So in order to maintain a low latency for users, we have to ensure enough GPU resources are immediately available for the service. And in order to find out what that optimal users-GPU-performance ratio was, I needed to run benchmarks for each model under varying conditions.”
Think of it like this: If one container can serve a maximum of 100 users while maintaining a latency of less than 10 seconds, eventually adding additional users will degrade performance and lead to a longer response time. In order to maintain a sub-10 second response time, the autoscaler needs to recognize that an increase in users is imminent and scale up the amount of allocated resources accordingly. So after running benchmarks to determine the optimal ratio for each LLM model, Ragavan turned his focus to developing a new autoscaling framework.
As noted earlier, traditional autoscaling strategies, including the one used by Kubernetes’ HPA, use GPU utilization as a scaling metric, which can be misleading. For instance, an LLM pod may show low utilization if it is not actively serving requests, even though it may have a fully loaded model taking significant GPU memory. On the other end of the spectrum, transient spikes in utilization can signal an over-provisioning of resources. To solve this problem, Ragavan enhanced the Kubernetes HPA with a customized autoscaling mechanism that uses a model-specific metric known as KV cache utilization. KV cache utilization reflects how much GPU memory the attention cache actually occupies. Through more testing, Ragavan found that LLM model response time—or, Time To First Token (TTFT)—was extraordinarily sensitive to KV cache pressure. Increases in KV cache utilization correlated directly with increases in TTFT.
Once Ragavan established 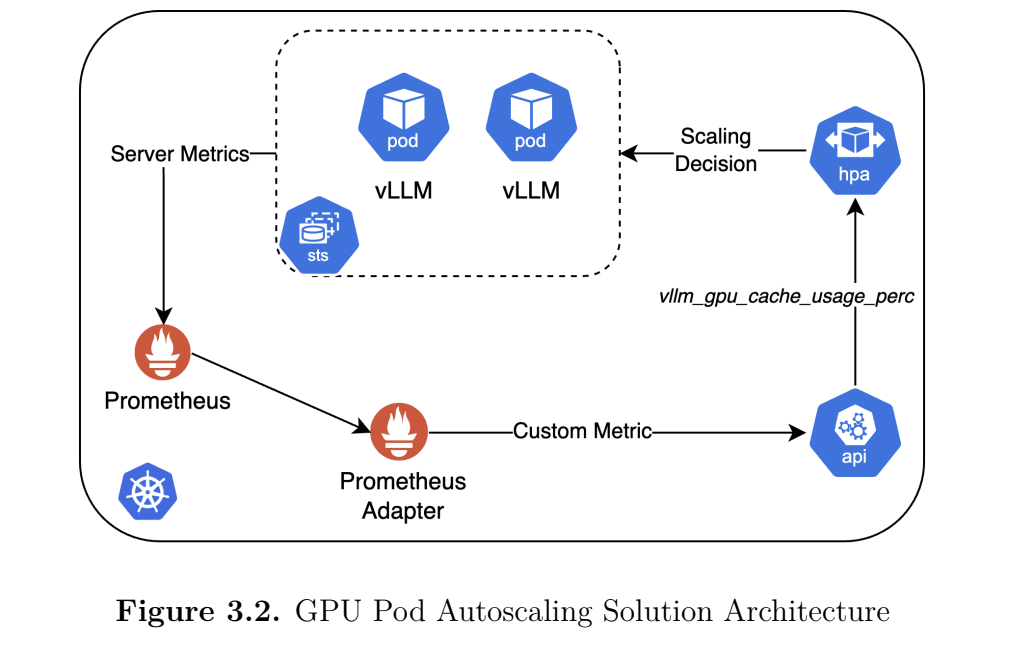 that KV cache utilization was the optimal choice as a proxy for system load, he needed to determine at what usage percentage a model’s performance began to suffer. For AnvilGPT, the magic number turned out to be approximately 52%—anything above this and the TTFT is negatively impacted. Another challenge in developing a successful autoscaling mechanism for LLM services is the high model load time. Creating a new pod requires huge (multi-billion parameter) models into GPU memory, which takes time. To offset this cold-start buffer time, Ragavan set the autoscaler usage threshold at 40%. Now, anytime the KV cache utilization for AnvilGPT exceeds 40%, the autoscaler triggers the creation of another pod and an increase in GPU resources.
that KV cache utilization was the optimal choice as a proxy for system load, he needed to determine at what usage percentage a model’s performance began to suffer. For AnvilGPT, the magic number turned out to be approximately 52%—anything above this and the TTFT is negatively impacted. Another challenge in developing a successful autoscaling mechanism for LLM services is the high model load time. Creating a new pod requires huge (multi-billion parameter) models into GPU memory, which takes time. To offset this cold-start buffer time, Ragavan set the autoscaler usage threshold at 40%. Now, anytime the KV cache utilization for AnvilGPT exceeds 40%, the autoscaler triggers the creation of another pod and an increase in GPU resources.
“When broken down, my autoscaler work was simply a scheduling problem in disguise,” says Ragavan. “Basically, we just want to schedule an increase in pods in a particular node. The mystery behind it lies in the details—how to know an increase is needed, and when to trigger that increase. For AnvilGPT, we now have answers to those questions.”
In the end, Ragavan’s customized autoscaler achieved a 70% reduction in TTFT for AnvilGPT, sustaining low latency and high throughput while also dynamically adjusting resources to improve resource allocation.
Career Development
Aside from providing an excellent avenue for completing his innovative MS thesis, being a part of RCAC gave Ragavan opportunities to further advance his career. He was able to attend multiple computing conferences during his time at RCAC. Listening to different presentations at these conferences is actually what led him to figure out the solutions for his two MS thesis projects. However, one notable conference experience proved valuable even beyond learning new software engineering skills.
Ragavan attended KubeCon 2024 in Salt Lake City, where he met Yuan Tang, a senior principal software engineer at Red Hat. Tang was based in West Lafayette and was very interested to learn of Ragavan’s work at Purdue. After discussing his MS thesis projects, highlighting different challenges and how he was addressing them, Ragavan thoroughly impressed Tang and was given an opportunity to interview with the Red Hat team. Fast-forward to early June, and Ragavan began working at Red Hat as a full-time software engineer.
“Not many people get to do that, right?” says Ragavan. “Right out of college, the thing I was studying and working on the last two years directly helped me get a job, working on the same types of problems. It’s a really good thing that not many people get, so I’m really grateful for the experience at RCAC that led to this.”
Thanks to his work at RCAC, Ragavan has also been given opportunities to publish and present at multiple international conferences. As noted earlier, he successfully presented on June 9 at the 2025 IEEE International Conference on Communications. He is also co-author on a paper that will be presented at PEARC25 in July. Undoubtedly, these will be the first of many conference presentations for Ragavan and RCAC is excited to see the impact of Vivek’s work at Red Hat.
“So in two years,” says Ragavan, “I am really indebted to everything RCAC has done for me. Working there was a really great experience. And really big thanks to Sarah, Erik, and Laura [Theademan], who provided me with these opportunities and guided me on my journey. Because of the experience and the work I was able to accomplish, I have ended up in a really good place right now.”
RCAC is equally grateful to Ragavan for his efforts while working at the center, and is thrilled to see where his hard work and talent will take him in the future. Erik Gough, a senior research scientist at RCAC, and one of Ragavan’s mentors, had a few words to add:
“It’s always great when we can match a student’s interests, expertise and desire to learn with a hard problem to solve on Anvil. Vivek’s work on AnvilGPT better positions us to be a national leader in provisioning LLM services for a broad research community.”
For more information about the CI-XP student program, please visit here.
To learn more about High-Performance Computing and how it can help you, please visit our “Why HPC?” page.
Anvil is one of Purdue University’s most powerful supercomputers, providing researchers from diverse backgrounds with advanced computing capabilities. Built through a $10 million system acquisition grant from the National Science Foundation (NSF), Anvil supports scientific discovery by providing resources through the NSF’s Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS), a program that serves tens of thousands of researchers across the United States.
Researchers may request access to Anvil via the ACCESS allocations process. More information about Anvil is available on Purdue’s Anvil website. Anyone with questions should contact anvil@purdue.edu. Anvil is funded under NSF award No. 2005632.
Written by: Jonathan Poole, poole43@purdue.edu