
Anvil used to advance AI 3D object detection
Researchers from the University of Virginia used Purdue’s Anvil supercomputer to advance the field of 3D computer vision by leveraging artificial intelligence (AI) methods. Their work, which has led to the production of numerous publications and conference presentations, could help with major breakthroughs in robotics and autonomous driving.
Dr. Zezhou Cheng is an Assistant Professor of Computer Science at the University of Virginia, where he leads the Computer Vision Lab. He and his graduate students have taken on a slew of research projects involving an advanced computer vision technique called 3D object detection. Traditional 2D object detection systems can locate and detect objects on flat images by analyzing the object’s horizontal and vertical properties. A major limitation, however, is a lack of depth data, meaning these systems cannot tell how big an object is, how far away it may be, or how it is oriented in space. 3D object detection systems overcome this problem by analyzing point clouds, which are created with data obtained from sensors such as LiDAR and stereo cameras. This depth data is crucial for applications such as self-driving vehicles, robotics, and augmented reality systems, all of which need precise spatial awareness to function properly.
Cheng’s group has been quite prolific in the computer vision research space over the past two years—five publications in 2025, five so far in 2026, as well as a preprint currently awaiting approval. Their output is impressive, but conducting AI-driven research at such a pace requires access to cutting-edge high-performance computing (HPC) systems. For this, Cheng turned to the Anvil supercomputer.
Cheng applied for an allocation on Anvil through the National Artificial Intelligence Research Resource (NAIRR) Pilot program. Once approved, Cheng and his students had access to multiple NVIDIA H100 GPUs, allowing them to train and develop AI models at a rate unimaginable on traditional computing platforms.
“Anvil is wonderful. One of the best, I would say,” says Cheng. “There are many H100 GPUs available. Students could schedule jobs on 12 to 14 H100s, which enabled us to train very large models. A single GPU is too limited. On other systems, we would have to wait up to three days for 8 A100s [NVIDIA’s older GPU chip], but on Anvil, we could launch 8 H100s within a few hours.”
One particularly 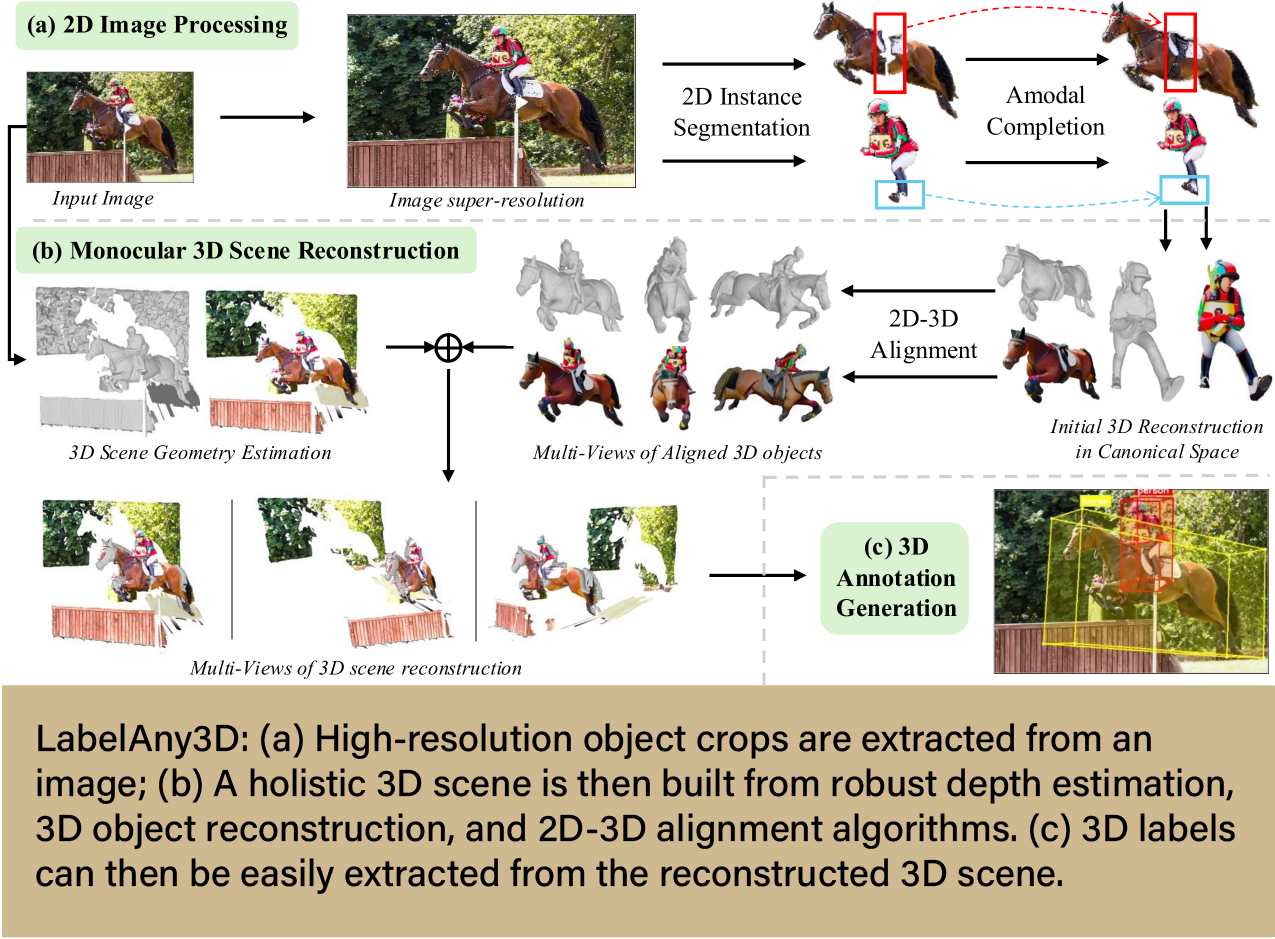 impactful project was LabelAny3D, an automatic 3D annotation pipeline that efficiently generates 3D bounding boxes for objects across arbitrary categories through a technique known as monocular 3D object detection. This technique relies not on point clouds and depth data collected from sensors, but from a single RGB image. Monocular methods are more efficient and accessible than approaches that require specialized sensors, and researchers believe they are key to deriving real-world impact from 3D object detection systems.
impactful project was LabelAny3D, an automatic 3D annotation pipeline that efficiently generates 3D bounding boxes for objects across arbitrary categories through a technique known as monocular 3D object detection. This technique relies not on point clouds and depth data collected from sensors, but from a single RGB image. Monocular methods are more efficient and accessible than approaches that require specialized sensors, and researchers believe they are key to deriving real-world impact from 3D object detection systems.
Cheng and his group developed LabelAny3D as a way to overcome a major challenge in AI model training—annotation. Annotation refers to labeling individual images used within AI model training datasets. Typically, this is a time and labor-intensive process that needs to be conducted by a human. Current monocular 3D detection models were designed with autonomous driving in mind, so the people annotating the datasets focused on cars and pedestrians at the expense of anything else. This inevitably leads to models that struggle with images “in-the-wild.”
“Because it is useful for autonomous driving, people have the motivation to annotate vehicles and pedestrians,” says Cheng. “That’s why current 3D datasets contain limited categories, not including categories such as animals or food. LabelAny3D is designed to fill this gap and unlock 3D detection in-the-wild.”
With LabelAny3D, Cheng and team have developed a framework that automatically reconstructs 3D representations from 2D images and produces high-quality 3D bounding box annotations. Using LabelAny3D, the group then developed a new benchmark for open-vocabulary monocular 3D detection that includes over 80 object categories, most of which are absent from existing 3D datasets. Future researchers can now use Cheng’s 3D annotation pipeline to create higher-quality AI training datasets as well as more robust and functional 3D recognition systems for real-world applications.

Cheng presented LabelAny3D at the Conference on Neural Information Processing Systems (NeurIPS) 2025, a renowned international machine learning and computational neuroscience conference. While there, Cheng also presented another research project enabled by Anvil: Frame In-N-Out. He has since gone on to present other Anvil-supported work at various conferences, including the International Conference on 3D Vision (3DV) 2026, the International Conference on Learning Representations (ICLR) 2026, the Computer Vision and Pattern Recognition (CVPR) Conference 2026, and the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2026. Needless to say, this level of high-quality AI-driven work would not be possible without a powerful HPC resource like Anvil.
Another great aspect of having access to the Anvil supercomputer is the robust support team that comes with it. Cheng was thrilled with the level of support he received from the Anvil team.
“The Anvil team,” says Cheng, “they really spent a lot of time helping me solve some storage limitation issues, and we really appreciate their help. One problem was that we needed to download a very large dataset—probably 30TB or more—and the team offered to download it for us and provide it on the system in a shared space so future users could access it as well.”
Cheng continues, “They also provided same-day feedback for questions like adding new users or increasing SUs. They were very helpful.”
For more information on Cheng and the Computer Vision Lab’s research, please visit: Publications
To learn more about High-Performance Computing and how it can help you, please visit our “Why HPC?” page.
Anvil is one of Purdue University’s most powerful supercomputers, providing researchers from diverse backgrounds with advanced computing capabilities. Built through a $10 million system acquisition grant from the National Science Foundation (NSF), Anvil supports scientific discovery by providing resources through the NSF’s Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS), a program that serves tens of thousands of researchers across the United States. Anvil also supports advanced artificial intelligence research as an official resource provider of the National Artificial Intelligence Research Resource (NAIRR) Pilot.
Researchers may request access to Anvil via the ACCESS allocations process or through the NAIRR allocations process. More information about Anvil is available on Purdue’s Anvil website. Anyone with questions should contact anvil@purdue.edu. Anvil is funded under NSF award No. 2005632.
Publications citing Anvil:
- Wentao Zhou, Xuweiyi Chen, Vignesh Rajagopal, Jeffrey Chen, Rohan Chandra, Zezhou Cheng. Stereo4DWalker: Learning 4D-aware Embodied Urban Navigation from Internet Stereo Videos. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026
- Xuweiyi Chen, Wentao Zhou, and Zezhou Cheng. Wildrayzer: Self-supervised large view synthesis in dynamic environments. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026.
- Xuweiyi Chen, Wentao Zhou, Aruni RoyChowdhury, and Zezhou Cheng. Point-moe: Towards
cross-domain generalization in 3d semantic segmentation via mixture-of-experts. In International Conference on Learning Representations (ICLR), 2026.
- Xuweiyi Chen and Zezhou Cheng. Semantic-free procedural 3d shapes are surprisingly good teachers. In International Conference on 3D Vision (3DV), 2026.
- Jin Yao, Hao Gu, Xuweiyi Chen, Jiayun Wang, and Zezhou Cheng. Open vocabulary monocular 3d object detection. In International Conference on 3D Vision (3DV), 2026.
- Jin Yao, Radowan Mahmud Redoy, Sebastian Elbaum, Matthew B. Dwyer, and Zezhou Cheng. Labelany3d: Label any object 3d in the wild. In Neural Information Processing Systems (NeurIPS), 2025.
- Boyang Wang, Xuweiyi Chen, Matheus Gadelha, and Zezhou Cheng. Frame in-n-out: Unbounded controllable image-to-video generation. In NeurIPS (NeurIPS), 2025.
Written by: Jonathan Poole, poole43@purdue.edu