
PBS to Slurm Transition Review
We would like to thank all our community cluster partners and researchers for your patience as we have moved all eight of our High Performance Clusters to a new batch job scheduler. This has been a project that demanded large amounts of effort on the part of the entire Research Computing organization, and we have been very grateful for your understanding and willingness to contribute in a positive way to the effort.
Switching to a widely-used, open-source scheduler will allow us to continue to provide the community cluster service to you in a cost-effective way, be more in line with HPC centers all over the world, and have modern tools to implement the forward-looking resource management capabilities many of you have asked about.
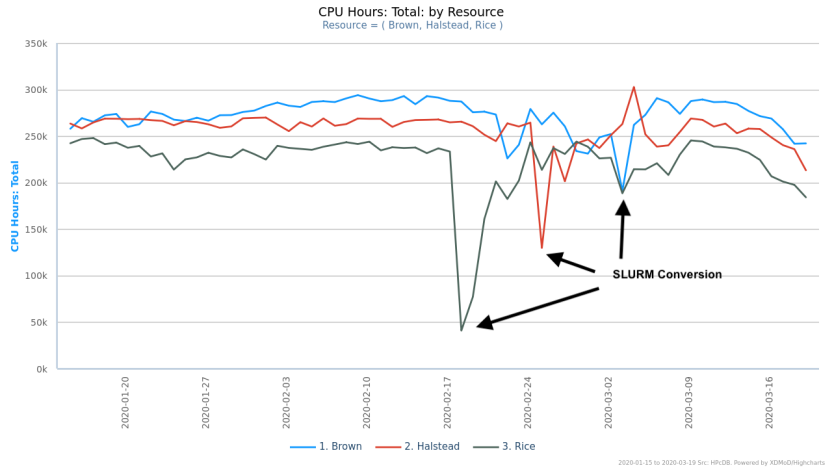
In the broad picture, this conversion has gone very well - utilizing the conversion documentation, training materials, and face-to-face consultations, you and the students in your labs all have adapted quickly, and the clusters quickly returned to 95% of their pre-conversion steady-state utilization.
However, at the individual queue level, we know from the feedback you’ve shared that many of you have noticed that the Slurm scheduler configuration has not yet converged on scheduling your jobs in the way that you have become accustomed.
Community Cluster Scheduling Goals
To restate the goals for which we are aiming:
- Owner queue jobs are of top priority, and if the queue is not hitting resource limits, we expect no worse than 4 hours of queue time to start.
- Our goal: meeting the delivered average of 1.5 hours in queue that we had with PBS
- Standby queue jobs are of lower priority than owner queue jobs, and should not start unless no eligible owner queue jobs are able to be started
- Within standby (and within a given owner queue), the scheduler then should enforce fair and even delivery of cycles delivered among all the users, so that no one user monopolizes the queue
- We can verify this by seeing that over the course of a week, all standby users have consumed approximately the same amount of CPU-hours.
- Other suggestions? Please let us know. rcac-help@purdue.edu
With these goals in mind, and your feedback showing us real-world jobs that aren’t scheduling in the order that you or we expect, we have already made a number of adjustments to the algorithm to elicit the desired behavior from Slurm.
Changes, Bugs, and To-do List
For example, we have already:
- Adjusted the scheduler’s decision-making relative to the weights of Owner vs Standby (2/28, 3/4, 3/5)
- Then, at a lower magnitude, prioritized fairshare allocation of resources (3/11)
- Finally, at the smallest weight, given a boost for jobs proportional to the job’s age (3/11)
- Added some limits to cap a single user’s ability to consume an entire queue’s worth of resources (3/19)
- Adjusted the fairshare scheduler’s time window and decay rate
- Set PriorityFavorSmall to NO (3/16)
- Fine-tuned the scheduler’s decision-making on backfill (fitting smaller, shorter jobs into holes being set aside by Slurm to start future larger jobs) (3/16-3/18)
- Configured Gilbreth to reject CPU-only jobs, i.e. all Gilbreth jobs must request at least one GPU (3/31)
We have also found several bugs in the software that we are working with the Slurm developers on getting fixes, or working around:
- There is a bug where a large, ineligible job at the front of the queue in an owner queue can block other, smaller jobs in the owner queue from starting when they should be able to. (Workaround in place 3/9)
- XDG_RUNTIME_DIR and SESSION_MANAGER issue described below is a bug (Workaround in place 3/20)
Finally, we have deployed a number of quality-of-life fixes and tools focused around the user experience:
- The sinteractive command was deployed on all systems to simplify launching interactive Slurm jobs. (2/27)
- Configured Slurm to ignore #PBS directives in job scripts. (3/7)
- Fixes were deployed to prevent XDG_RUNTIME_DIR and SESSION_MANAGER variables from being exported into (mostly) interactive jobs to prevent errors like "XDG_RUNTIME_DIR /run/user/123456 does not exist!" (3/20)
Issues and functionality still being addressed:
- Torque and Moab allowed an explicit queue time target to use in scheduling decisions - “make sure that owner queue jobs don’t wait for more than 4 hours if resources are available".
- Tuning the weight factor for how the Slurm scheduler prioritizes based on job size is still to be evaluated.
- Reserving a pool of nodes for “debug” queue jobs, to start instantly
- Evaluate Slurm potentially using its knowledge of the Infiniband topology to allocate nodes within a job to be as near to each other as possible.
- Other suggestions? Please let us know rcac-help@purdue.edu
Most of what we expect to do will not be obvious unless you are keeping careful statistics of the entire cluster's job scheduling, but you may see some effects with respect to the type of jobs you are concerned with -- running in the standby queue vs your dedicated queue, single node vs multi-node jobs, batch vs interactive mode, high core-count vs single-core jobs, and other resource requests.
You can help us by letting us know through a message to rcac-help@purdue.edu if you see specific jobs that you think are being mishandled. In that event, please let us know the cluster and job id so we can diagnose it directly.
Thanks again for your patience. Our User community is the only irreplaceable component of our shared resource.