
Anvil supercomputer used to advance knowledge of nanotechnology
A researcher from Duke University is using Purdue’s Anvil supercomputer to study and explore the underlying physics of a nanotechnology known as DNA Origami.
Pranav Sharma is an Associate Researcher in the Biological and Soft Materials Modeling Lab at Duke University. He is using Anvil to develop and run a coarse-grained molecular model of nanoparticles in order to reverse-engineer a phenomenon called self-assembly, wherein nanoparticles spontaneously organize into higher-level structures due to intermolecular forces. Specifically, Sharma focused his project on DNA Origami, an emerging nanotechnology that takes advantage of the phenomenon of self-assembly as well as the properties inherent in DNA structures, with the ultimate goal of deepening the understanding of these structures and eventually leading to the development of a new nanoscale manufacturing paradigm.
DNA Origami
Deoxyribonucleic acid, or DNA, is a molecule that, 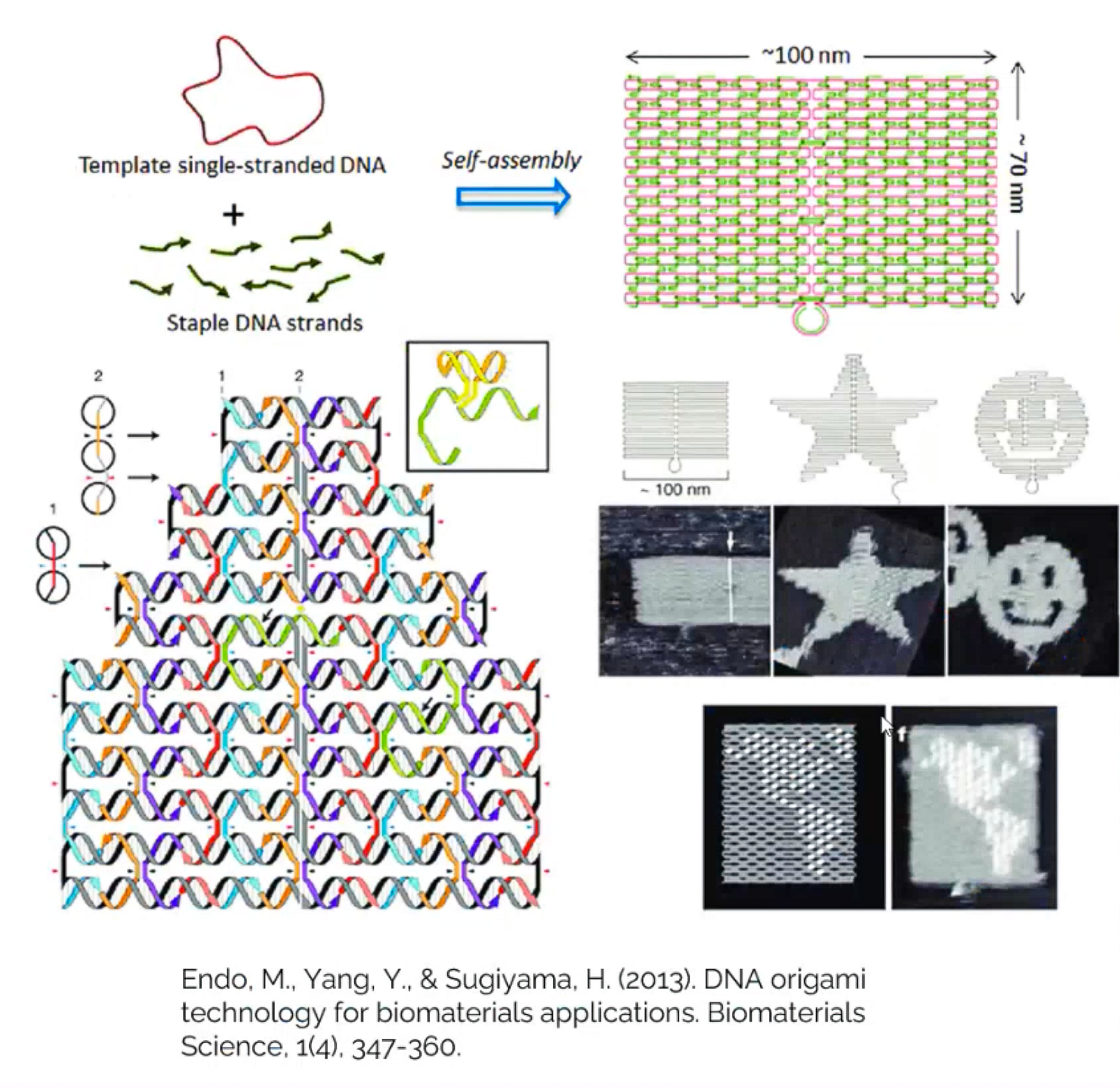 thanks to its double-helix structure, is excellent at storing information. In nature, DNA carries the genetic information responsible for the development, functioning, growth, and reproduction of almost all organisms. Starting in the 1980s, scientists began looking at DNA-based synthetic nanostructures to take advantage of the unique properties of DNA, and thus, the field of DNA nanotechnology was born. DNA origami is a branch of the DNA nanotechnology field. It involves folding a long, single-stranded DNA (the “scaffold”) into complex 2D and 3D objects by using hundreds of short single-stranded DNAs (called “staples”), via crossover base pairing. DNA origami has tremendous potential with a plethora of use cases across multiple domains: nanofabrication, nanophotonics and nanoelectronics, catalysis, computation, molecular machines, drug delivery, and bioimaging and biophysics, to name a few. The utilization of DNA origami is seemingly endless, but there are some obstacles that keep scientists from seizing its full potential.
thanks to its double-helix structure, is excellent at storing information. In nature, DNA carries the genetic information responsible for the development, functioning, growth, and reproduction of almost all organisms. Starting in the 1980s, scientists began looking at DNA-based synthetic nanostructures to take advantage of the unique properties of DNA, and thus, the field of DNA nanotechnology was born. DNA origami is a branch of the DNA nanotechnology field. It involves folding a long, single-stranded DNA (the “scaffold”) into complex 2D and 3D objects by using hundreds of short single-stranded DNAs (called “staples”), via crossover base pairing. DNA origami has tremendous potential with a plethora of use cases across multiple domains: nanofabrication, nanophotonics and nanoelectronics, catalysis, computation, molecular machines, drug delivery, and bioimaging and biophysics, to name a few. The utilization of DNA origami is seemingly endless, but there are some obstacles that keep scientists from seizing its full potential.
According to Sharma, one key limitation to optimizing DNA origami is a lack of knowledge of the underlying physics of molecular recognition, in particular, how multiple DNA tiles self-assemble to form complex materials. “My work focuses on this—once individual origami tiles have folded, what are the physics of making multiple tiles come together? We need to create complex hierarchical materials with control over composition and geometry across many spatial scales, and DNA origami seems to be the way we can achieve that. But there is currently a lot of mystery behind this level of creating DNA origami assembly.”
This mystery is precisely what Sharma set out to solve when he embarked on his research project over three years ago, as a sophomore studying Biomedical Engineering and Computer Science. Another group had previously studied the process of molecular recognition between DNA origami tiles experimentally, and Sharma used this research as a starting point. He took the general parameters from their work and designed a computational model of the experiment, with the hopes of: 1) seeing convergence between the experimental and computational results (showing that the model is valid), and 2) creating a model that could be predictive of future experimental results. If successful, this computational model could shed light on how self-assembly works on a molecular level.
“We had a setup of sequences,” says Sharma, “with blunt-end driven molecular recognition, but the relationship between the sequence that a tile presents and the thermodynamic free energy of that reaction is not clear. So we wanted to make a coarse-grained model of these experimental tiles so that we can predict thermodynamic performance for a given sequence.”
The computational models were built to simulate 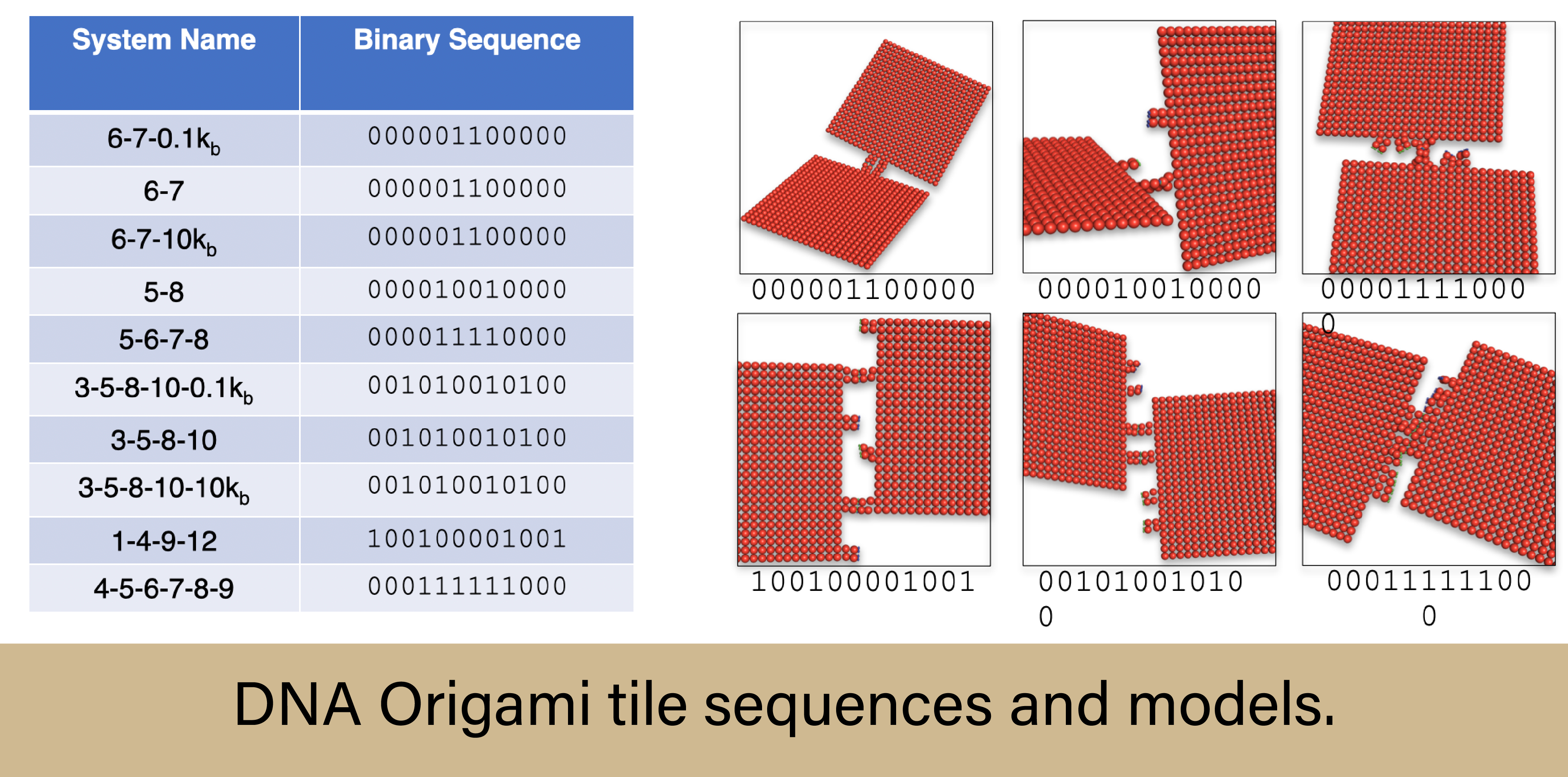 ten different DNA origami “tiles,” with each tile having a unique binary sequence. The sequence represents the specific layout of “patches” on the edge of a tile. Spots can either be an active patch, meaning exposed bases of another active patch can engage in strong stacking interactions with the spot (a.k.a. a binding group, and represented by a 1), or inactive patch, where no interaction happens (represented by a 0). There are 12 spots on the outer edges of each tile. These 12 spots, or the sequence, can be designed and manipulated however a scientist sees fit, based on the inclusion or exclusion of staple strands during assembly. As an example, four active patches can be sandwiched together with four inactive patches on either side (000011110000). Or the active patches could be more spread out throughout the sequence (001010010100). However they are constructed, tiles with matching sequences will find each other in solution and bind, effectively giving scientists control over each tile’s placement and rotation in larger assemblies. But knowing the mechanics of how these tiles bind will allow scientists to develop better, more reliable binding sequences, which in turn will allow for better and more reliable DNA origami structures.
ten different DNA origami “tiles,” with each tile having a unique binary sequence. The sequence represents the specific layout of “patches” on the edge of a tile. Spots can either be an active patch, meaning exposed bases of another active patch can engage in strong stacking interactions with the spot (a.k.a. a binding group, and represented by a 1), or inactive patch, where no interaction happens (represented by a 0). There are 12 spots on the outer edges of each tile. These 12 spots, or the sequence, can be designed and manipulated however a scientist sees fit, based on the inclusion or exclusion of staple strands during assembly. As an example, four active patches can be sandwiched together with four inactive patches on either side (000011110000). Or the active patches could be more spread out throughout the sequence (001010010100). However they are constructed, tiles with matching sequences will find each other in solution and bind, effectively giving scientists control over each tile’s placement and rotation in larger assemblies. But knowing the mechanics of how these tiles bind will allow scientists to develop better, more reliable binding sequences, which in turn will allow for better and more reliable DNA origami structures.
“Basically,” says Sharma, “this work is an exploration of how the spacing and sequencing of binding groups on a nanoparticle interface affects the thermodynamics of binding.”
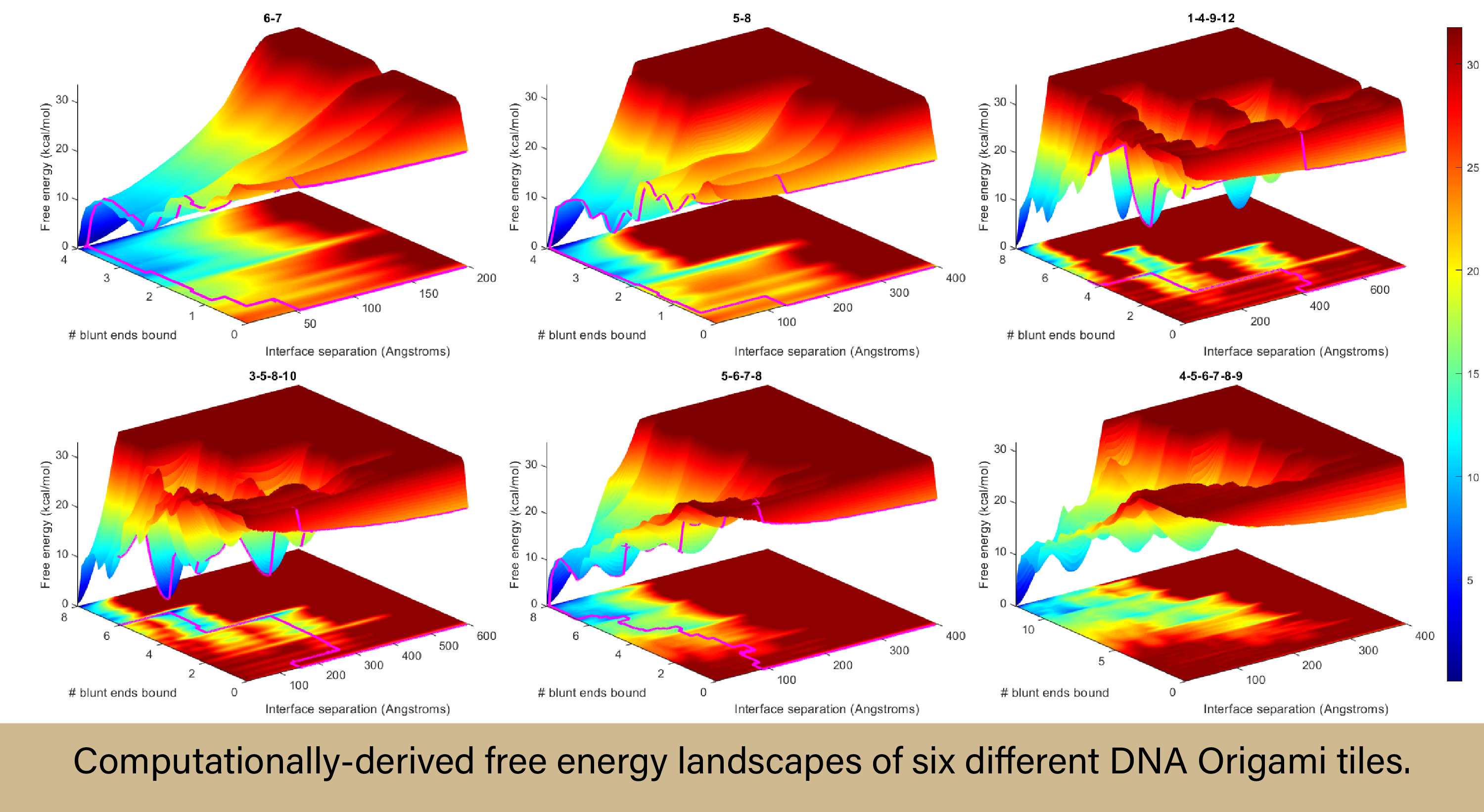
Six of the DNA origami tiles that Sharma is studying in his computations were pulled directly from the previously completed experimental study so that he could compare results. To develop the models, Sharma needed to create multiple physical parameters (mechanical characteristics) for the DNA strands, such as bending and stretching. He then needed to assign energetic penalties to the motions and fluctuations that the models would undergo at the proper scale. Think of it like this—everything has an equilibrium state, and the further away from that state you go, the more unlikely it is to occur, so the higher the energetic penalty would be. Next he calibrated the energetics of the strong interactions that drive tile binding, followed by more calculations: charge-charge interactions, Coulombic interactions in a charged solution, etc. Eventually, Sharma made it to the centerpiece of the project, computational metadynamics. Metadynamics is a simulation method used to compute the free energy landscape in complex biomolecular systems. When simulating a system with metadynamics, the simulation will add energy to the landscape and push the system out of the energy “well” (its highly favorable energetic state) until every configuration in the system is sampled equally, regardless of how energetically favorable it is. For the sake of simplicity, these metadynamics simulations are what can highlight for scientists the binding sequences that would work best for their intended purpose. And metadynamics simulations require an enormous amount of computational power.
“These calculations are very large. Every time I send a single tile system out for simulation to continue calculating the energy landscape, I’m using one or two nodes for four days straight. It’s very computationally intensive and the output is written to files that are almost 130 GB total for each tile.”
Sharma utilized Anvil to run his computations. Although a young undergraduate when he first started this project, Sharma is now no stranger to HPC systems, having used multiple supercomputers across different projects. He found that while Anvil had tremendous power and speed to offer for his simulations, the more exciting aspect of Purdue’s supercomputer was its reliability.
“Anvil is great. I’ve used many supercomputers, and Anvil has performed more reliably than many of these other systems. Often, I would leave a calculation running and come back to find something had gone wrong, only to run it the exact same way and have it work perfectly, but on Anvil, this was never an issue. I was able to just leave it running, and that’s the best thing you can ask for.”
Sharma’s project is now close to completion, and thus far, he is very happy with the results. Of course, such a large project would be almost impossible to complete in isolation. Sharma wanted to specifically mention the tremendous value provided by his PI, Gaurav Arya, Professor in the Department of Mechanical Engineering and Materials Science at Duke University, and Sebastian Sensane, an Assistant Professor at the Department of Physics, Cleveland State University, and thank them both for all of their help. Without them, notes Sharma, the project would not have been possible.
For more information on Sharma and his research, please contact: pranav.sharma@duke.edu.
To learn more about HPC and how it can help you, please visit our “Why HPC?” page.
Anvil is Purdue University’s most powerful supercomputer, providing researchers from diverse backgrounds with advanced computing capabilities. Built through a $10 million system acquisition grant from the National Science Foundation (NSF), Anvil supports scientific discovery by providing resources through the NSF’s Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS), a program that serves tens of thousands of researchers across the United States.
Researchers may request access to Anvil via the ACCESS allocations process. More information about Anvil is available on Purdue’s Anvil website. Anyone with questions should contact anvil@purdue.edu. Anvil is funded under NSF award No. 2005632.
Written by: Jonathan Poole, poole43@purdue.edu