
Policies, Helpful Tips and FAQs
Here are details on some policies for research users and systems.
Software Installation Request Policy
The Anvil team will go to every reasonable effort to provide a broadly useful set of popular software packages for research cluster users. However, many domain-specific packages that may only be of use to single users or small groups of users are beyond the capacity of staff to fully maintain and support. Please consider the following if you require software that is not available via the module command:
- If your lab is the only user of a software package, Anvil staff may recommend that you install your software privately, either in your home directory or in your allocation project space. If you need help installing software, the Anvil support team may be able to provide limited help.
- As more users request a particular piece of software, Anvil may decide to provide the software centrally. Matlab, Python (Anaconda), NAMD, GROMACS, and R are all examples of frequently requested and used centrally-installed software.
- Python modules that are available through the Anaconda distribution will be installed through it. Anvil staff may recommend you install other Python modules privately.
If you're not sure how your software request should be handled or need help installing software please contact us at Help Desk.
Helpful Tips
We will strive to ensure that Anvil serves as a valuable resource to the national research community. We hope that you the user will assist us by making note of the following:
- You share Anvil with thousands of other users, and what you do on the system affects others. Exercise good citizenship to ensure that your activity does not adversely impact the system and the research community with whom you share it. For instance: do not run jobs on the login nodes and do not stress the filesystem.
- Help us serve you better by filing informative help desk tickets. Before submitting a help desk ticket do check what the user guide and other documentation say. Search the internet for key phrases in your error logs; that's probably what the consultants answering your ticket are going to do. What have you changed since the last time your job succeeded?
- Describe your issue as precisely and completely as you can: what you did, what happened, verbatim error messages, other meaningful output. When appropriate, include the information a consultant would need to find your artifacts and understand your workflow: e.g. the directory containing your build and/or job script; the modules you were using; relevant job numbers; and recent changes in your workflow that could affect or explain the behavior you're observing.
- Have realistic expectations. Consultants can address system issues and answer questions about Anvil. But they can't teach parallel programming in a ticket and may know nothing about the package you downloaded. They may offer general advice that will help you build, debug, optimize, or modify your code, but you shouldn't expect them to do these things for you.
- Be patient. It may take a business day for a consultant to get back to you, especially if your issue is complex. It might take an exchange or two before you and the consultant are on the same page. If the admins disable your account, it's not punitive. When the file system is in danger of crashing, or a login node hangs, they don't have time to notify you before taking action.
For GPU jobs, make sure to use --gpus-per-node command, otherwise, your job may not run properly.
Link to section 'Helpful Tools' of 'Helpful Tips' Helpful Tools
The Anvil cluster provides a list of useful auxiliary tools:
| Tool | Use | |
|---|---|---|
myquota |
Check the quota of different file systems. | |
flost |
A utility to recover files from snapshots. | |
showpartitions |
Display all Slurm partitions and their current usage. | |
myscratch |
Show the path to your scratch directory. | |
jobinfo |
Collates job information from the sstat, sacctand squeue SLURM commands to give a uniform interface for both current and historical jobs. |
|
sfeatures |
Show the list of available constraint feature names for different node types. | |
myproject |
Print the location of my project directory. | |
mybalance |
Check the allocation usage of your project team. | |
wait_time |
Show the predicted start time of a given job. To use, enter wait_time [-j | –job_id] job_id for the desired job. |
Frequently Asked Questions
Some common questions, errors, and problems are categorized below. Click the Expand Topics link in the upper right to see all entries at once. You can also use the search box above to search the user guide for any issues you are seeing.
About Anvil
Frequently asked questions about Anvil.
Can you remove me from the Anvil mailing list?
Your subscription in the Anvil mailing list is tied to your account on Anvil which was granted to you through an ACCESS allocation. If you are no longer using your account on Anvil, you can contact your PI or allocation manager to remove you from their Anvil allocation.
How is Anvil different than Purdue Community Clusters?
Anvil is part of the national Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) ecosystem and is not part of Purdue Community Clusters program. There are a lot of similarities between the systems, yet there are also a few differences in hardware, software and overall governance. For Purdue users accustomed to the way Purdue supercomputing clusters operate, the following summarizes key differences between RCAC clusters and Anvil.
Link to section 'Support' of 'How is Anvil different than Purdue Community Clusters?' Support
-
While Anvil is operated by Purdue RCAC, it is an ACCESS resource, and all support requests have to go through ACCESS channels rather than RCAC ones. Please direct your Anvil questions to the ACCESS Help Desk (https://support.access-ci.org/open-a-ticket) and they will be dispatched to us.
Link to section 'Resource Allocations' of 'How is Anvil different than Purdue Community Clusters?' Resource Allocations
Two key things to remember on Anvil and other ACCESS resources:
- In contrast with Community Clusters, you do not buy nodes on Anvil. To access Anvil, PIs must request an allocation through ACCESS.
- Users don't get access to a dedicated “owner” queue with X-number of cores. Instead, they get an allocation for Y-number of core-hours. Jobs can be submitted to any of the predefined partitions.
More details on these differences are presented below.
-
Access to Anvil is free (no need to purchase nodes), and is governed by ACCESS allocation policies. All allocation requests must be submitted via ACCESS Resource Allocation System. These allocations other than the Maximize ACCESS Request can be requested at any time.
Explore ACCESS allocations are intended for purposes that require small resource amounts. Researchers can try out resources or run benchmarks, instructors can provide access for small-scale classroom activities, research software engineers can develop or port codes, and so on. Graduate students can conduct thesis or dissertation work. To prepare a request, visit Prepare Requests.
Discover ACCESS allocations are intended to fill the needs of many small-scale research activities or other resource needs. The goal of this opportunity is to allow many researchers, Campus Champions, and Gateways to request allocations with a minimum amount of effort so they can complete their work. To prepare a request, visit Prepare Requests.
Accelerate ACCESS allocations support activities that require more substantial, mid-scale resource amounts to pursue their research objectives. These include activities such as consolidating multi-grant programs, collaborative projects, preparing for Maximize ACCESS requests, and supporting gateways with growing communities. To prepare a request, visit Prepare Requests.
Maximize ACCESS allocations are for projects with resource needs beyond those provided by an Accelerate ACCESS project, a Maximize ACCESS request is required. ACCESS does not place an upper limit on the size of allocations that can be requested or awarded at this level, but resource providers may have limits on allocation amounts for specific resources. To prepare a request, visit Prepare Requests.
-
Unlike the Community Clusters model (where you “own” a certain amount of nodes and can run on them for the lifetime of the cluster), under ACCESS model, you apply for resource allocations on one or more ACCESS systems, and your project is granted certain amounts of Service Units (SUs) on each system. Different ACCESS centers compute SUs differently, but in general SUs are always some measure of CPU-hours or similar resource usage by your jobs. Anvil job accounting page provides more details on how we compute SU consumption on Anvil. Once granted, you can use your allocation’s SUs until they are consumed or expired, after which the allocation must be renewed via established ACCESS process (note: no automatic refills, but there are options to extend the time to use up your SUs and request additional SUs as supplements). You can check your allocation balances on ACCESS website, or use a local
mybalancecommand in Anvil terminal window.
Link to section 'Accounts and Passwords' of 'How is Anvil different than Purdue Community Clusters?' Accounts and Passwords
-
Your Anvil account is not the same as your Purdue Career Account. Following ACCESS procedures, you will need to create an ACCESS account (it is these ACCESS user names that your PI or project manager adds to their allocation to grant you access to Anvil). Your Anvil user name will be automatically derived from ACCESS account name, and it will look something similar to
x-ACCESSname, starting with anx-. -
Anvil does not support password authentication, and there is no “Anvil password”. The recommended authentication method for SSH is public key-based authentication (“SSH keys”). Please see the user guide for detailed descriptions and steps to configure and use your SSH keys.
Link to section 'Storage and Filesystems' of 'How is Anvil different than Purdue Community Clusters?' Storage and Filesystems
-
Anvil scratch purging policies (see the filesystems section) are significantly more stringent than on Purdue RCAC systems. Files not accessed for 30 days are deleted instantly and automatically (on the filesystem's internal policy engine level). Note: there are no warning emails!
-
Purdue Data Depot is not available on Anvil, but every allocation receives a dedicated project space (
$PROJECT) shared among allocation members in a way very similar to Data Depot. See the filesystems section in the user guide for more details. You can transfer files between Anvil and Data Depot or Purdue clusters using any of the mutually supported methods (e.g. SCP, SFTP, rsync, Globus). -
Purdue Fortress is available on Anvil, but direct HSI and HTAR are currently not supported. You can transfer files between Anvil and Fortress using any of the mutually supported methods (e.g. SFTP, Globus).
-
Anvil features Globus Connect Server v5 which enables direct HTTPS access to data on Anvil Globus collections right from your browser (both uploads and downloads).
Link to section 'Partitions and Node Types' of 'How is Anvil different than Purdue Community Clusters?' Partitions and Node Types
-
Anvil consists of several types of compute nodes (regular, large memory, GPU-equipped, etc), arranged into multiple partitions according to various hardware properties and scheduling policies. You are free to direct your jobs and use your SUs in any partition that suits your jobs’ specific computational needs and matches your allocation type (CPU vs. GPU). Note that different partitions may “burn” your SUs at a different rate - see Anvil job accounting page for detailed description.
Corollary: On Anvil, you need to specify both allocation account and partition for your jobs (
-A allocationand-p partitionoptions), otherwise your job will end up in the defaultsharedpartition, which may or may not be optimal. See partitions page for details. -
There are no
standby,partnerorowner-type queues on Anvil. All jobs in all partitions are prioritized equally.
Link to section 'Software Stack' of 'How is Anvil different than Purdue Community Clusters?' Software Stack
-
Two completely separate software stacks and corresponding Lmod module files are provided for CPU- and GPU-based applications. Use
module load modtree/cpuandmodule load modtree/gputo switch between them. The CPU stack is loaded by default when you login to the system. See example jobs section for specific instructions and submission scripts templates.
Link to section 'Composable Subsystem' of 'How is Anvil different than Purdue Community Clusters?' Composable Subsystem
-
A composable subsystem alongside of the main HPC cluster is a uniquely empowering feature of Anvil. Composable subsystem is a Kubernetes-based private cloud that enables researchers to define and stand up custom services, such as notebooks, databases, elastic software stacks, and science gateways.
Link to section 'Everything Else' of 'How is Anvil different than Purdue Community Clusters?' Everything Else
-
The above list provides highlights of major differences an RCAC user would find on Anvil, but it is by no means exhaustive. Please refer to Anvil user guide for detailed descriptions, or reach out to us through ACCESS Help Desk (https://support.access-ci.org/open-a-ticket)
Logging In & Accounts
Frequently asked questions related to Logging In & Accounts.
Questions
Common login-related questions.
Can I use browser-based Thinlinc to access Anvil?
Link to section 'Problem' of 'Can I use browser-based Thinlinc to access Anvil?' Problem
You would like to use browser-based Thinlinc to access Anvil, but do not know what username and password to use.
Link to section 'Solution' of 'Can I use browser-based Thinlinc to access Anvil?' Solution
Password based access is not supported at this moment. Please use Thinlinc Client instead.
For your first time login to Anvil, you will have to login to Open OnDemand with your ACCESS username and password to start an anvil terminal and then set up SSH keys. Then you are able to use your native Thinlic client to access Anvil with SSH keys.
What is my username and password to access Anvil?
Link to section 'Problem' of 'What is my username and password to access Anvil?' Problem
You would like to login to Anvil, but do not know what username and password to use.
Link to section 'Solution' of 'What is my username and password to access Anvil?' Solution
Currently, you can access Anvil through:
-
SSH client:
You can login with standard SSH connections with SSH keys-based authentication to
anvil.rcac.purdue.eduusing your Anvil username. -
Native Thinlinc Client:
You can access native Thinlic client with SSH keys.
-
Open OnDemand:
You can access Open OnDemand with your ACCESS username and password.
What if my ThinLinc screen is locked?
Link to section 'Problem' of 'What if my ThinLinc screen is locked?' Problem
Your ThinLinc desktop is locked after being idle for a while, and it asks for a password to refresh it, but you do not know the password.

Link to section 'Solution' of 'What if my ThinLinc screen is locked?' Solution
If your screen is locked, close the ThinLinc client, reopen the client login popup, and select End existing session.
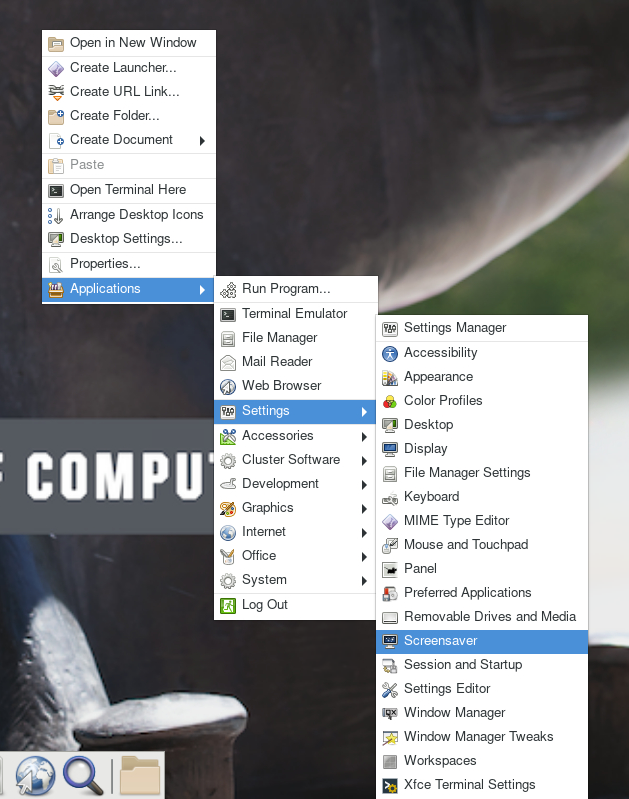
To permanently avoid screen lock issue, right click desktop and select Applications, then settings, and select Screensaver.
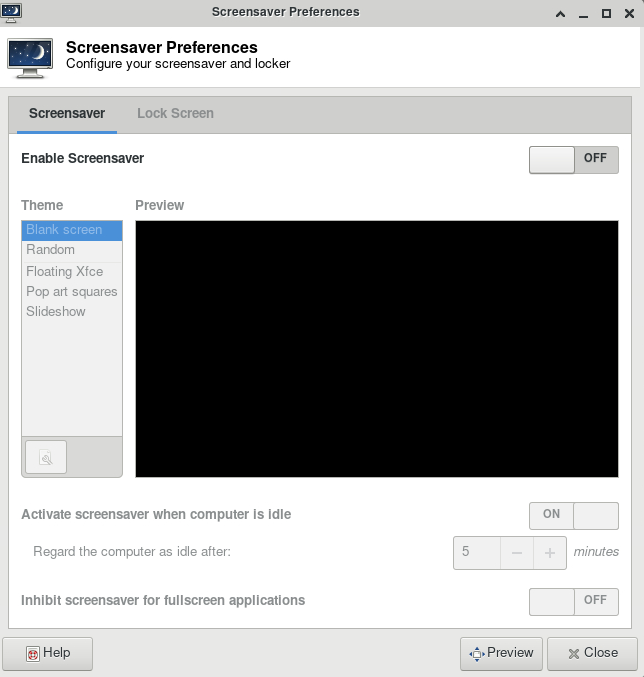
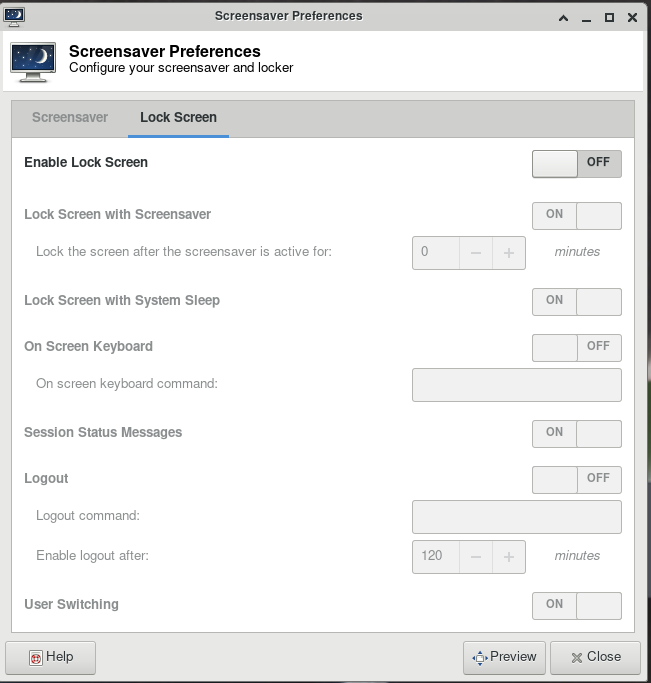
Under Screensaver, turn off the Enable Screensaver, then under Lock Screen, turn off the Enable Lock Screen, and close the window.
Jobs
Frequently asked questions related to running jobs.
Errors
Common errors and potential solutions/workarounds for them.
Close Firefox / Firefox is already running but not responding
Link to section 'Problem' of 'Close Firefox / Firefox is already running but not responding' Problem
You receive the following message after trying to launch Firefox browser inside your graphics desktop:
Close Firefox
Firefox is already running, but not responding. To open a new window,
you must first close the existing Firefox process, or restart your system.
Link to section 'Solution' of 'Close Firefox / Firefox is already running but not responding' Solution
When Firefox runs, it creates several lock files in the Firefox profile directory (inside ~/.mozilla/firefox/ folder in your home directory). If a newly-started Firefox instance detects the presence of these lock files, it complains.
This error can happen due to multiple reasons:
- Reason: You had a single Firefox process running, but it terminated abruptly without a chance to clean its lock files (e.g. the job got terminated, session ended, node crashed or rebooted, etc).
- Solution: If you are certain you do not have any other Firefox processes running elsewhere, please use the following command in a terminal window to detect and remove the lock files:
$ unlock-firefox
- Solution: If you are certain you do not have any other Firefox processes running elsewhere, please use the following command in a terminal window to detect and remove the lock files:
- Reason: You may indeed have another Firefox process (in another Thinlinc or Gateway session on this or other cluster, another front-end or compute node). With many clusters sharing common home directory, a running Firefox instance on one can affect another.
- Solution: Try finding and closing running Firefox process(es) on other nodes and clusters.
- Solution: If you must have multiple Firefoxes running simultaneously, you may be able to create separate Firefox profiles and select which one to use for each instance.
Jupyter: database is locked / can not load notebook format
Link to section 'Problem' of 'Jupyter: database is locked / can not load notebook format' Problem
You receive the following message after trying to load existing Jupyter notebooks inside your JupyterHub session:
Error loading notebook
An unknown error occurred while loading this notebook. This version can load notebook formats or earlier. See the server log for details.
Alternatively, the notebook may open but present an error when creating or saving a notebook:
Autosave Failed!
Unexpected error while saving file: MyNotebookName.ipynb database is locked
Link to section 'Solution' of 'Jupyter: database is locked / can not load notebook format' Solution
When Jupyter notebooks are opened, the server keeps track of their state in an internal database (located inside ~/.local/share/jupyter/ folder in your home directory). If a Jupyter process gets terminated abruptly (e.g. due to an out-of-memory error or a host reboot), the database lock is not cleared properly, and future instances of Jupyter detect the lock and complain.
Please follow these steps to resolve:
- Fully exit from your existing Jupyter session (close all notebooks, terminate Jupyter, log out from JupyterHub or JupyterLab, terminate OnDemand gateway's Jupyter app, etc).
- In a terminal window (SSH, Thinlinc or OnDemand gateway's terminal app) use the following command to clean up stale database locks:
$ unlock-jupyter - Start a new Jupyter session as usual.